Learning Multi-Level Features with Matryoshka Sparse Autoencoders
Learning Multi-Level Features with Matryoshka Sparse Autoencoders
Author: https://arxiv.org/search/cs?searchtype=author&query=Bussmann,+B, https://arxiv.org/search/cs?searchtype=author&query=Nabeshima,+N, https://arxiv.org/search/cs?searchtype=author&query=Karvonen,+A, https://arxiv.org/search/cs?searchtype=author&query=Nanda,+N
Category: Steering
Status: Done
URL: https://arxiv.org/abs/2503.17547
< Abstract >
- SAE가 NN의 concept을 extract할 수 있어 interpretation의 powerful tool로 사용되고 있음
- SAE의 dictionary size (sae decoder의 column vector 개수 또는 sae hidden의 dim)를 어떻게 정할까?
- sparse하게 만들면 더 많은 concept을 저장하지만 high-level concept이 잘게 나뉘게 됨 (missing or warped)
- Matryoshka SAE: increasing size의 nested dictionary를 train하고 smaller dictionary로 input을 reconstruct 시키려는 시도 without using larger dicitonary
- feature들을 hierarchical하게 organize 하려 함
- smaller dictionary: general concept 학습이 목표
- larger dictionary: high-level feature를 absorb하는데 incentive가 없이 specific concept 학습이 목표
1. Introduction
- SAE가 NN의 internal representation 해석에 많이 쓰이더라
- NN의 dense activation을 sae로 sparse한 latent space로 mapping 시키는 것을 통해 model의 decision making process에 대한 insight를 얻을 수 있을 것으로 기대
- 그러나 실제로 sparsity는 완벽하지 않은 proxy 지표일 뿐임
- SAE 쓸 때 가능한 적은 activate된 neuron으로 표현하도록 하는데 이게 pathological solution이라고 주장
- 현실은 다양한 개념이 hierarchical하지만 이걸 flat한 hidden feature로 만드는 것이 문제가 아니냐
- i.e. punctuation mark 같은 general concept과 question mark와 같은 specific concept
- SAE는 sparsity penalty에 의해 general concept을 feature splitting하여 여러 개의 sepcific으로 나누게 됨
- 더 큰 문제는 feature absorption: 특정 latent가 원래 더 general한 concept에 반응했는데 split에 의해 나뉘게 된 경우
- i.e. 원래 E로 시작하는 모든 단어에 대해서 activate 되다가 Elephant에 의해 activate 되는 경우가 split 되어 빠진 상황
- 원래 feature가 Elephant를 제외한 모든 E에 대해 activate 됨: 원본 의미도 망가짐 (모든 경우를 cover하지 않고 hole이 발생)
- 더 큰 문제는 feature absorption: 특정 latent가 원래 더 general한 concept에 반응했는데 split에 의해 나뉘게 된 경우
- 추가로 activate 되는 latent 수를 sparse 하게 하려고 하다 보면 너무 특이하고 복합적인 개념에만 activate 되는 feature 들도 생김
- red, triangle에 각각 반응하다가 red triangle이라는 하나에 반응하도록 바뀜
- 이런 류의 문제는 sae hidden의 dim이 늘어날록 심해짐
- Deep learning과는 scale 하면 performance가 악화되는 경우도 있음
- 현재는 다른 사이즈 sae를 여러개 sweep으로 train하여 각각 평가해서 좋은거 쓰는데 costly
- Matryoshka sae: 동시에 increasing size의 nested sae를 train시킴
- subset of latents만 이용하여 input을 reconstruction 시키는 것이 목표
- 이를 통해 specialized latent가 general latent의 feature를 absorb하는 것을 방지하려고 함
- 결과 적으로 Matryoshka SAE는:
- feature absorption 최소화
- disentangled latent representation (sae decoder vector cosine sim으로 측정)
- probing & steering performance increase
- increase size of dictionary에도 perf 유지를 달성
2. Background
2-1. Interpretability with SAE
- SAE에 대한 간단한 설명
- SAE Latents $f(x)$: SAE Encoder를 통과시켜서 나온 결과물 (feature라고 함)
- Activation Function σ: non-negativity & sparsity를 enforce하는 활성화 함수
- Approximated Reconstruction $\hat{x}$: SAE Decoder가 복원한 vector, 원본과 차이를 최소화하는게 목표
2-2. Challenges in Scaling SAEs
- SAE training의 핵심은 reconstruction quality와 sparsity를 유지하는 것
- Sparsity는 L1 Regularization이나 TopK 같은 L0 Constraint로 가능한 적은 latent로 represent하게 할 수 있음
- Superposition에서 interpretable feature를 extract하려면 sparsity는 필요함, 그러나 문제 발생:
- Feature Splitting: 하나의 concept가 여러 latent로 나뉘게 되는 현상
- Feature Absorption: 하나의 concept중 일부만 다른 latent가 반응하게 되어 불완전해지는 것 (hole이 생김)
- i.e. 원래 요일에 반응하던 latent → 나뉘어 월요일에 반응 과 나머지 요일에 반응하게 바뀜
- Feature Composition: 독립적인 concept이 enforced sparsity에 의해 하나로 합쳐지는 것
- Sparsity-driven Distortion이라고 하겠음
- sparsity-driven distortion은 dictionary size가 커질수록 증가
- Reconstruction해서 원본과 비슷하게 나오는 것에는 문제 없으므로 recon objective로는 탐지 불가
2-3. Matryoshka Representation Learning
- varying level of granularity를 가지는 info를 single embedding vector에 담으려는 시도
- loss function이 key distinction임
3. Matryoshka SAE
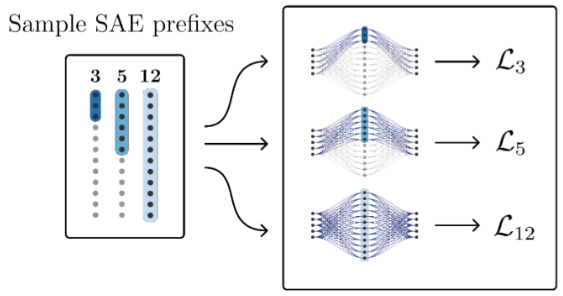
- $M$: matryo SAE의 dictionary size들의 set
- $m_i$: 첫 $m_i$개의 sae latent만 사용하여 input x를 recon한 recon $\hat{x}$를 만들게 하는 prefix
3-1. Training Objective
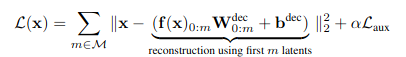
- multiple scale에서 good reconstruction을 enforce하는 것이 목적
- 3개, 5개 , … , n개의 latent를 사용할 때 모두 잘해야함
- Early latent는 general, latent 개수가 늘어날 수록 specific feature에 특화되는 것을 기대
3-2. BatchTopK Activation Function
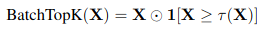
- Batch $X$ = [$x_1, x_2, …, x_B$]: input $x$를 Batch 단위 B개로 묶음
- entire Batch에서 B * K개 largest activation을 추출: τ(X)
- 그 이하는 zero out 시킴: sparsity 유지
- 원래 TopK와 추출되는 총 개수는 동일하지만 example마다 active latent의 개수는 vary함
- 주장하는 바: vector마다 정보량이 다르기 때문에 일괄적으로 K개 사용은 이상함
- 정보량 많으면 뽑힌 개수 ≥ K 가능
- 정보량 적으면 뽑힌 개수 ≤ K 가능
- 주장하는 바: vector마다 정보량이 다르기 때문에 일괄적으로 K개 사용은 이상함
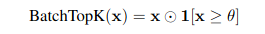
- Inference time에는 threshold로 변경하여 threshold value 넘으면 activate로 판단
- threshold value는 training동안 원하는 평균 sparsity를 유지할 수 있는 값으로 조절
- 원래 TopK와 추출되는 총 개수는 동일하지만 example마다 active latent의 개수는 vary함
⇒ BatchTopK를 먼저 적용하여 Activate/Deactivate Latent를 구분
⇒ 그 뒤 Dict Size 별로 recon 진행
4. Experiments
- Matryoshka SAE의 feature absorption & fragmentation 방지를 보여주는 것이 목표
- 3 increasing complexity로 experiment 진행
- Toy Model로 feature absorption
- small 4-layer TinyStories model로 획득한 feature들에 대한 investigation
- Gemma-2-2B 아키텍처 사용하여 benchmark 테스트
4-1. Toy Model Demo of Feature Absorption
- Main purpose는 feature absorption을 matryo sae가 막을 수 있다는 것을 보이는 것
- 실험 세팅:
- input/output dim=20, hidden dim=20
- feature는 20개, binary로 turned on or turned off상태만 존재
- $R^{d=20}$의 unique direction과 mapping 됨
- 결국 activate된 feature들의 선형 결합으로 input을 만드는 것이 목표
- parent가 activate 되어야 child가 activate 될 수 있는 상황
- i.e. parent = punctuation mark, child = comma를 생각해보자
-
기존 sae의 문제점은 sparsity를 enforce 하여 feature absorption이라는 문제가 발생
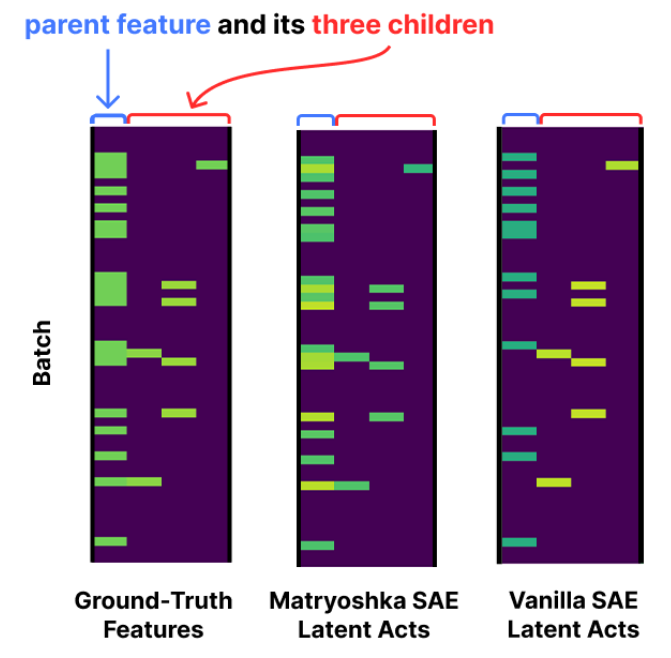
- 20개의 feature 중 parent feature 1개와 연결된 children 3개를 발췌한 것
- ground-truth와 matryo는 child가 activate 될 때 parent도 activate 됨
- feature absorption이 없는 바라던 상황
- vanilla는 direction을 표현할 때 parent를 사용하지 않고 child 만으로도 표현이 가능함
-
SAE의 문제점 중 하나로 묘사한 feature absorption이 보이는 것

-
- SAE들이 학습한 learned decoder vector와 ground truth vector의 cosine similarity를 측정한 heatmap
- Matryo는 child는 child만, parent는 parent와만 비슷하도록 vector를 학습
- Vanilla는 Feature Absorption이 발생하여 child가 parent와도 어느정도 유사함을 보임
- 원하는 바는 distinct한 vector 두개가 학습되어 동시에 activate 되어 어떠한 direction을 만드는 것이 바람직하지만 Vanilla의 경우 어느 정도 유사하게 학습되어 둘 중 하나만 activate해서도 표현이 가능하게 되는 문제가 발생
4-2. TinyStories Investigation
- 4-layer Transformer (768 hidden dim), TinyStories dataset 학습
-
SAE의 dictionary size를 키워가며 (30, 100, 300, 1K, 3K, 10K latents) feature 변화를 확인


- 일반적인 SAE의 경우 dict size가 증가할수록 hole이 발생하였음
- 원래는 female 관련된 모든 token에 반응하다가 lily, sue 같은 특수한 경우에만 반응하는 latent가 생기고 원래 corresponding latent는 그 경우 반응을 멈춤 ⇒ feature absorption
4-3. Larger-Scale Validation with Gemma-2-2B
- Gemma-2-2B 모델에 dict size를 { 2048, 6144, 14336, 30720, 65536 } 으로 설정하여 5단계 nested 학습
- SAE는 5개 학습했고 각 각 20, 40, 80, 160, 320 개의 latent를 activate시켜 복원하게 학습
- 12번 layer의 residual에서 학습
- 다른 6개 SAE architecture들과 비교, SAE Bench사용
- Evaluation 시에는 Full dict size 사용
- Gemma-2-2B 모델에 dict size를 { 2048, 6144, 14336, 30720, 65536 } 으로 설정하여 5단계 nested 학습
- SAE는 5개 학습했고 각 각 20, 40, 80, 160, 320 개의 latent를 activate시켜 복원하게 학습
- 12번 layer의 residual에서 학습
- 다른 6개 SAE architecture들과 비교, SAE Bench사용
- Evaluation 시에는 Full dict size 사용
4-3-1. Reconstruction & Downstream Performance
- Standard methods에 비해 Matryo SAE는 slightly worse recon을 보여줌
- Expected된 결과: Matryo SAE의 nested recon이 split이나 absorption을 막음 ⇒ 완벽한 복원은 힘들어 지는 결과
- 그러나 조금 다르게 recon 된 vector를 다시 Language Model에 넣고 Cross Entropy를 측정하면 loss는 높지 않음
- Matryo SAE에 의해 성능이 감소하지는 않는
4-3-2. Feature Absorption and Splitting
- SAE를 scaling하면 발생하는 문제: absorption & splitting을 Matryo가 줄이는 것을 보이는 것이 목표
- First-letter classification로 보여줄것임
- 일단 SAE 들어가기 전 각 token에 대 llm activation을 첫 글자에 따라 classification 할 수 있는 classifier를 학습 ⇒ 특정 activation이 이 classifier를 통과하면 어떤 letter로 시작하는지 train 단계 이후에는 알 수 있음
-
추후 first letter class에 해당하는 sae latent를 찾아서 (방법은 알려주지 않음) classifier로 분류한 first letter인데도 불구하고 activate 되지 않는 경우를 확인 ⇒ feature absorption: 다른 latent가 해당 input의 feature를 표현하고 있음
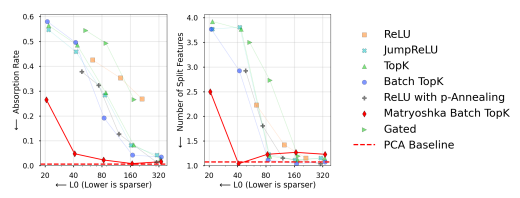
- absorption rate 이 가장 낮고 first letter를 capture 하기 위해 activate 되는 feature 개수도 가장 적음을 확인 ⇒ Matryo는 feature splitting이 없음
4-3-3. Feature Composition Analysis
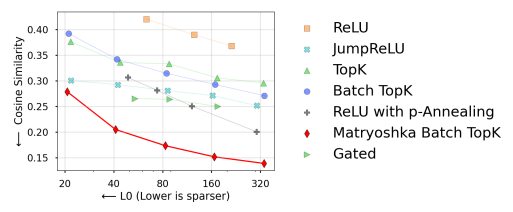
- SAE의 latent간 cosine similarity를 측정, average가 높으면 높을수록 multiple latent가 비슷한 의미에 fire된다는 뜻 (Composition)
- Matryo가 제일 좋았음
4-3-4. Scaling SAEs
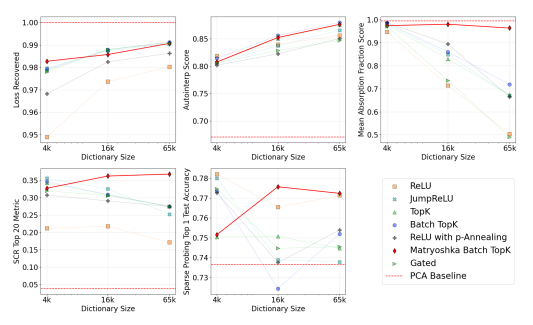
- dictionary 수를 늘려도 matryo는 모든 지표에서 발전하거나 유지했음
- Counterparts는 떨어지는 모습을 보였음
5. Limitation
- Matryo SAE: recon은 약간 낮지만 downstream task perf는 향상됨
- recon이 중요한 task에서는 쓰지 마라
- training time도 nested 때문에 늘어남: 실험에서 5개 different dict size로 했는데 50% 시간 증가함
- SAE가 감지한 feature가 human interpretable하거나, practical utility가 있지 않을 수 있음
6. Discussion and Conclusion
- SAE를 scaling할 때 발생하는 sparsity 관련 challenge를 해결할 수 있는 새로운 variant를 present함
- nested dict를 사용하여 hierarchical feature learning을 강제
- feature absorption을 억제, concept isolation 발전시킴