Mixture-of-Subspaces in Low-Rank Adaptation
Mixture-of-Subspaces in Low-Rank Adaptation
이 논문은 Low-Rank Adaptation (LoRA) method에서 보다 더 많은 하위 subspace를 혼합할 수 있는 방법, MoSLoRA를 제안한다.
LoRA (Low-Rank Adaptation)
LLM 같은 대규모 모델은 방대한 데이터와 파라미터로 인해 좋은 성능을 보이지만 이로 인해 fine-tuning 과정에서 전체 파라미터를 학습시키는 것은 어렵다. 이러한 단점을 보안하기 위한 PEFT (parameter-efficient fine-tuning)이 발전되어왔다.
LoRA는 PEFT의 일종으로 상당히 적은 수의 파라미터만을 학습시켜 전체 파라미터를 fine-tuning 한 것 만큼의 성능을 보인다.
\[xW_0+x\Delta W=xW_0+xAB , A \in \mathbb{R}^{d_1\times r}, B \in \mathbb{R}^{r\times d_2}\]LoRA는 fine-tuning 시 업데이트되는 파라미터 즉, $\Delta W$가 내재적으로는 low rank일 것이라는 가정으로부터 출발한다. 따라서 전체 파라미터를 업데이트하는 것이 아닌 low rank인 $AB$를 업데이트함으로써 비슷한 효과, 그러나 효율적인 학습을 노리는 것이다.
LoRA는 $AB$로 $d_1\times r +r\times d_2$ 의 파라미터를 가지지만, 실제로는 $d_1 \times d_2$의 파라미터를 효과를 낸다. LoRA는 저랭크 행렬 $A$, $B$를 사용하여 파라미터 수를 크게 줄인다.
따라서 LoRA는 기존의 파라미터 $W_0$는 건드리지 않고 새로운 $AB$를 업데이트한 후 나중에 $W_0$로 융합하는 방법을 사용한다.
Two-subspaces-mixing LoRA
기존의 LoRA 방식에서 \(xAB = x \begin{bmatrix} A_1 & A_2 \end{bmatrix} \begin{bmatrix} B_1 \\ B_2 \end{bmatrix} = x(A_1B_1 + A_2B_2)\)로 생각할 수 있다. ( $A_1, A_2 \in\mathbb{R}^{d_1\times\frac{r}{2}}, B_1, B_2 \in\mathbb{R}^{\frac{r}{2}\times d_2}$)
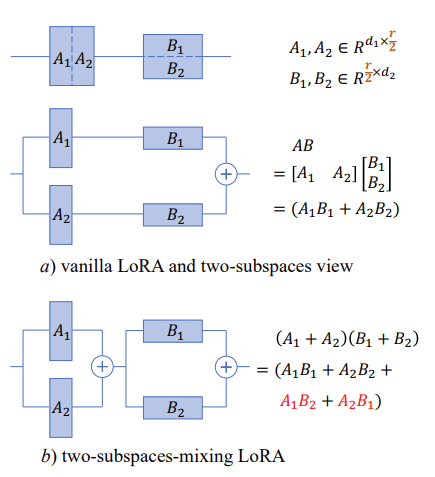
Figure 1.
이 논문에서는 A와 B를 결합하는 방식을 약간 변형해 봄으로써 이 matrix A, B를 보다 복잡하고 잘 섞는 방법을 제안한다. 위 Figure 1의 b가 이 논문에서 처음 접근한 방식이다. \(xAB=x\begin{bmatrix}A_1 & A_2\end{bmatrix}\begin{bmatrix} B_1 \\ B_2 \end{bmatrix}=x(A_1B_1+A_2B_2)\) 이 방식을 $x(A_1+A_2)(B_1+B_2)=x(A_1B_1+A_2B_2+A_1B_2+A_2B_1)$으로 약간 변형해주면 기존의 term은 물론 $A_1B_2+A_2B_1$이라는 새로운 term을 포함하는 것을 알 수 있다. 이를 해당 논문에서는 학습 영역 A, B를 더 복잡하게 mixing해서 새로운 정보 ($A_1B_2+A_2B_1$에 해당하는)를 얻을 수 있다고 설명한다.
위 방법을 더욱 일반화해보자. 단순히 \(\begin{bmatrix}A_1 & A_2\end{bmatrix}\begin{bmatrix} B_1 \\ B_2 \end{bmatrix}\)를 \((A_1+A_2)(B_1+B_2)\)로 바꾸어 2개의 term을 얻을 수 있었으니 $A$와 $B$를 더 잘게, column별로 쪼개보면 더욱 새로운 term을 얻을 수 있지 않을까?라는 접근이다. 그렇게 변형한 방법이 Two-subspaces-mixing LoRA 방법이다.
column으로 쪼갠다고 그냥 $(A_1+A_2+…+A_r)(B_1+B_2+…+B_r)$ 이렇게 곱하는 건 아니고 두 개씩 세트를 짝을 지어 다음 처럼 mixing한다.
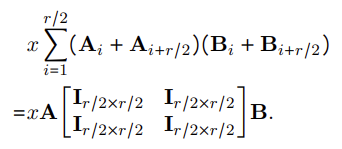
위 방법의 \(\begin{bmatrix} I_{\frac{r}{2}\times\frac{r}{2}} & I_{\frac{r}{2}\times\frac{r}{2}} \\ I_{\frac{r}{2}\times\frac{r}{2}} & I_{\frac{r}{2}\times\frac{r}{2}} \end{bmatrix}\)을 butterfly factor라고 하는데, 푸리에 변환에서 효율적인 선형 변환을 위한 행렬으로 속도 면에서 효율성이 있다고 하는거 같다.
아무튼 이렇게 2개로 짝지어서 mixing 했을 때 성능 향상이 있었다고 한다.
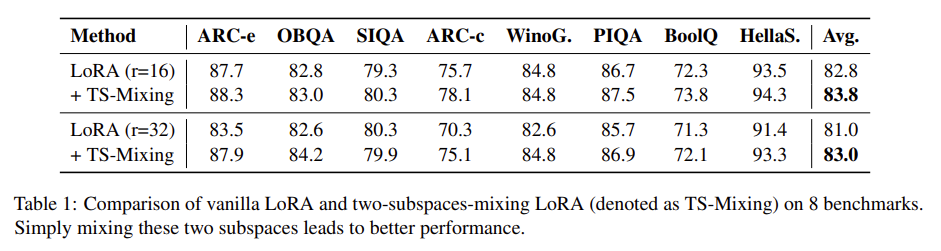
MoSLoRA
Vanilla LoRA 방법은 $xAB=xAI_{r\times r}B$로 A와 B를 identity matrix를 mixer로 하여 섞은 것으로 볼 수 있고 Two-subspaces-mixing LoRA는 butterfly factor를 mixer로 하여 A와 B를 섞은 것으로 볼 수 있다. 이를 일반화된 형태로 제공하면 $AWB$로 $W$라는 mixer가 subspaces를 혼합하는 것으로 볼 수 있다.
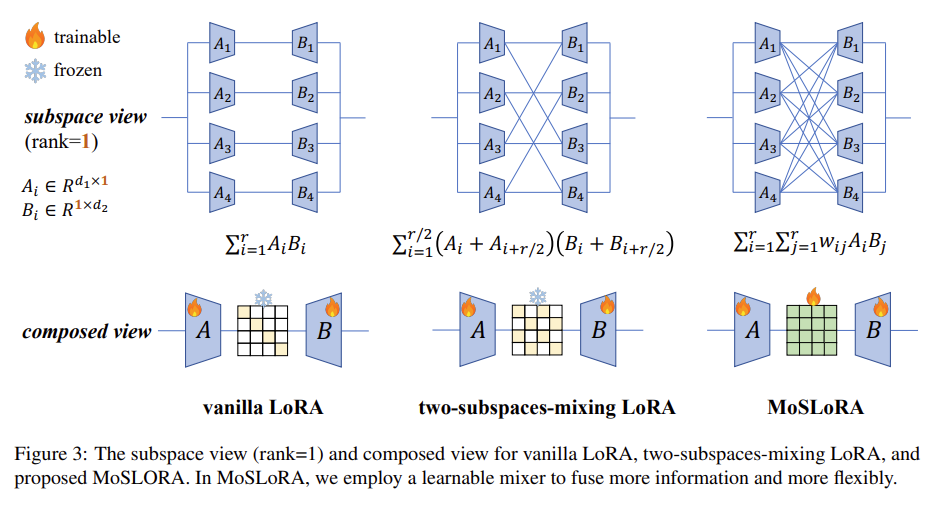
Figure 2.
MoSLoRA는 이 mixer 또한 특정 값을 주지 말고 학습시키자는 아이디어에서 나온 방법이다. $AWB$에서 $W$라는 가중치가 추가되었지만 이는 $r \times r$사이즈로 규모에는 크게 영향을 미치지 않을 것이다. 아무튼 이러한 방식으로 $A$와 $B$ 두 영역을 섞는 방식 조차 학습에 맡기는 것이 MoSLoRA이다.
MoSLoRA는 선형변환이기 때문에, 초깃값이 좋지 않으면 영향을 많이 미친다. 해당 논문에서는 실험할 때, Vanilla LoRA와 MoSRoLA의 A에 Kaiming uniform distribution, B에 zero matrix를 적용하였고 W에는 Kaiming uniform distribution 그리고 orthogonal matrix를 적용하였을 때, 성능이 좋았다.
MoSLoRA는 Commonsence Reasoning 지표에서 다른 baseline에 비해 효율적이면서도 높은 성능을 보였으며 그 외 multi-modal 환경에서도 좋은 성능을 보인다.
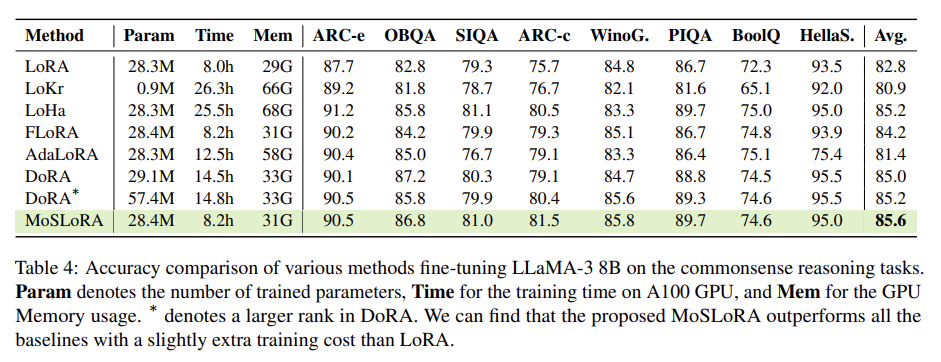
Conclusion
이 논문은 LoRA를 subspace 관점에서 재해석하여 subspace를 단순히 mixing해도 성능이 향상된다는 것을 발견하였다. 제안하는 방법은 mixer 초기화에 따라 성능이 민감하여 최적 초기화 전략을 연구할 필요가 있다.