ReMindRAG: Low-Cost LLM-Guided Knowledge Graph Traversal for Efficient RAG
ReMindRAG: Low-Cost LLM-Guided Knowledge Graph Traversal for Efficient RAG
Date: March 18, 2026 2:26 PM
Paper: ReMindRAG: Low-Cost LLM-Guided Knowledge Graph Traversal for Efficient RAG (NeurIPS’25 poster)
GitHub: https://github.com/kilgrims/ReMindRAG
📕 Introduction
기존 RAG에서 Multi-hop 추론과 넓은 범위의 의존성을 커버하기 위해, 지식 그래프(Knowledge Graph)를 사용한 RAG (KG-RAG) 연구가 진행되고 있다.
기존 KG-RAG에서 정보 검색을 위해 PPR 알고리즘이나 GNN과 같은 딥러닝 기반 접근법을 사용하는데, 이는 모호한 의미적 관계를 포착하기 어렵다는 단점이 존재한다.
최근에는 LLM이 노드를 탐색하는 방법을 사용하는 방식으로 RAG 성능을 향상시켰지만, LLM 호출 비용이 상당하고 생성된 결과에 노이즈가 포함되는 경우가 많다.
저자는 그래프를 검색하고, 검색한 경로를 저장 (Retrieve and Memorize) 하는 ReMindRAG를 제안한다. ReMindRAG의 핵심은 ‘LLM-guided KG Traversal’과 ‘Memory Replay’ 이 두 가지 요소이며, 처음 조우한 쿼를 탐색한 경로를 저장해두었다가 비슷한 쿼리가 들어올 때 저장된 경로를 찾아내는 것이 본 논문의 핵심이다.
📒 Methodology
1. Graph Construction - Contextual Skeleton Network
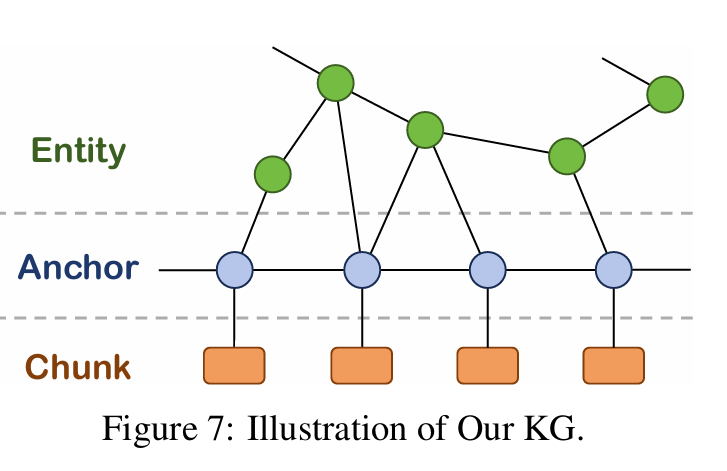
그래프의 노드와 엣지의 종류는 다음과 같다.
- Node: entity, chunk
- Edge: entity-entity, entity-chunk
Anchor 노드는 각 chunk의 요약된 정보가 한 두 문장으로 담겨 있음. 이는 Chunk의 제목 역할을 하며, 노드 탐색 시 Chunk를 바로 찾는 것이 아니라 anchor 노드를 거쳐서 chunk를 찾게된다. 그래프 생성 순서는 아래와 같다.
Text Chunking → Named Entity Recognition → Relation Triple Extraction → Knowledge Graph Building
Named Entity Recognition, Relation Triple Extraction은 프롬프트를 이용해서 추출한다.
이때, 두 엔티티 노드에 대해서 임베딩 유사도가 일정 수준을 넘으면 (> threshold: 0.7) 두 엔티티를 동의어로 보고 단일 엔티티 노드로 통합한다.
2. Graph Traversal
가장 먼저, 탐색을 시작할 Seed node를 선정해야 함. 주어진 쿼리와 임베딩 유사도가 가장 높은 Top-k 노드를 지식 그래프가 구축된 ChromaDB 에서 검색하여 얻어냄.
- 사용한 임베딩 모델: nomic-ai/nomic-embed-text-v2-moe
그렇게 선정된 Seed node들은 초기엔 edge가 없는 하나의 서브 그래프( $S$ )로 형성된다.
📕 LLM-Guided KG Traversal 정리
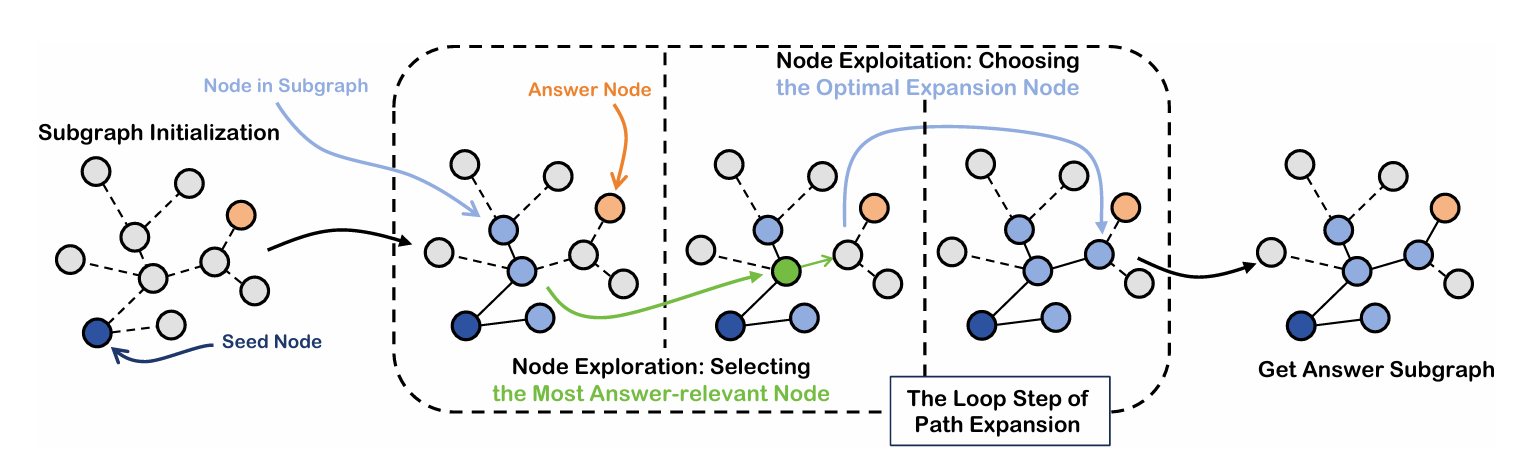
- 정답과 가장 관련이 있을 법한 노드 $a$를 주어진 서브 그래프 $S$ 안에서 찾는다.
- LLM이 $a$를 중심으로 이웃 노드 $a_{neighbor}\notin S$ 중에서 정답에 가장 가까운 $a_{neighbor}$ 하나를 선택하고, DFS 탐색을 수행한다.
- (Forward) $a_{neighbor}$가 적합하다고 판단되면, 서브 그래프 $S$ 에 포함시키고 $a$를 $a_{neighbor}$로 대체하여 2번으로 돌아간다.
- (Backward) $a_{neighbor}$가 적합하지 않다고 판단되면 지금까지 포함한 $a_{neighbor}$들을 제거하지 않고 냅둔다.
※ 주의 ※ Backward는 마지막 노드로 되돌아오는 게 아니다.
- 2번 과정을 모두 거치고 서브 그래프 $S$에 대해 평가한다. 정보가 충분하다고 판단하면 그래프 탐색을 종료하고, 그렇지 않다면 다시 1번으로 되돌아간다.
⚙️ 참고 사항
- 논문에서는 쿼리를 서브 쿼리로 나누어 각 서브 쿼리마다 seed node를 얻는 방법을 제안했으나, 실제 평가에서는 서브 쿼리를 사용하지 않고 평가했음 (논문 Appendix B.1 참고)
- ‘Efficient Subgraph Expansion via Memory Replay’ 과정을 설명할 때 언급하겠지만, 사실 맨 처음 쿼리가 들어올 때, LLM-Guided KG Traversal 과정을 바로 진행하지 않는다. 현재 그림은 서브 그래프의 seed node가 단 1개인 간단한 예시를 보여주고 있을 뿐임을 알아두자.
지금까지는 쿼리가 처음 들어올 때 (First Query) 서브 그래프를 탐색하는 과정이었고, 다음은 해당 서브 그래프의 path를 기억하는 방법, 비슷하거나 동일한 쿼리가 들어올 때 탐색하는 방법(Similar/Same Query)이다.
📕 Memorizing the Traversal Experience
memorize은 반드시 LLM이 쿼리에 대해 정답을 생성한 이후에 진행함. 엣지 임베딩을 업데이트 **함으로써 path를 memorize하는 방향으로 진행된다.
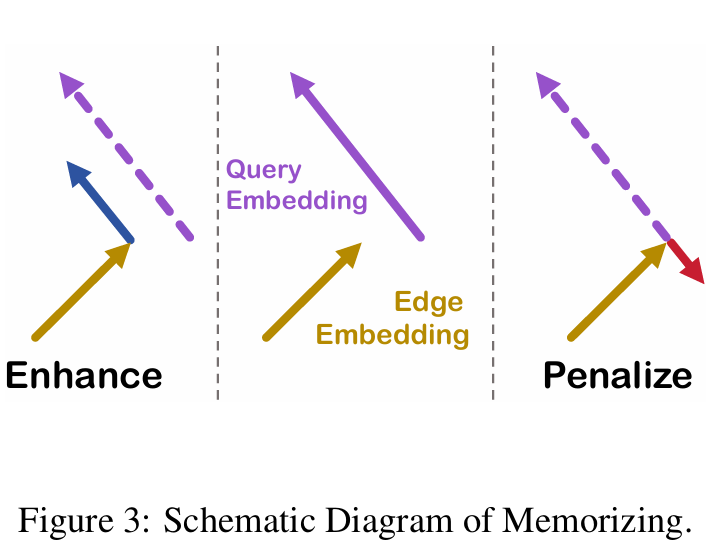
- Weight Function: $\delta(x)=\frac{2}{\pi}\cos\Big(\frac{\pi}{2}|x|_2\Big)$
- Effective Path: $\hat{v}=v+\delta(v)\cdot\frac{q}{|q|_2}$
- Ineffective Path: $\hat{v}=v-\delta(\frac{v\cdot q}{|q|_2})\cdot\frac{v\cdot q}{|q|_2}$
위의 $v\in R^K$는 임베딩 벡터, $K$는 임베딩 차원, $q$는 LLM에 의해 생성된 쿼리 임베딩이다.
Effective Path에 대해서 엣지 임베딩이 쿼리 임베딩의 방향에 가깝도록 업데이트 되고, Ineffective Path에 대해서 엣지 임베딩이 쿼리 임베딩과 반대되는 방향으로 업데이트 된다.
이때, Weight Function은 엣지의 가중치를 의미하는 것이 아니고 임베딩이 움직이는 정도를 조절하는 가중치 함수이다. 초기 엣지 임베딩의 값은 zero vector로 시작하기 때문에, 더 많은 가중치가 부여된다. 이후 엣지 임베딩을 이어서 업데이트 하게 되면 자연스럽게 가중치가 작아지므로 움직임이 덜하게 된다.
아래는 위 수식의 이해를 돕기 위한 그래프이다.
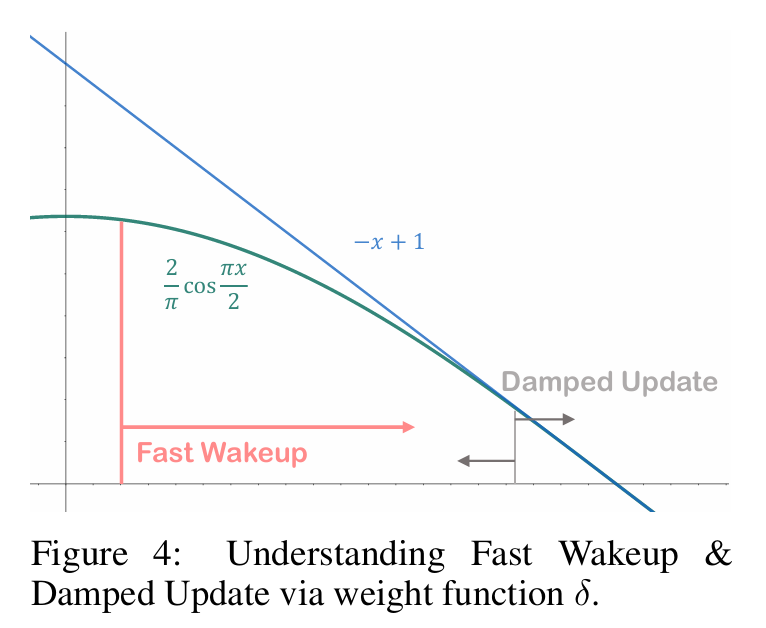
x축은 $|x|_2$ 값이고, y축은 $\delta(x)$ 값이다. 함수 모양을 보면 알 수 있다시피, norm 값이 증가할수록 (엣지 임베딩이 업데이트 될 수록) 가중치 $\delta(x)$가 줄어드는 형태임을 확인할 수 있다.
⚙️ 참고 사항
- 논문에서 Ineffective Path에 대해 패널티를 부여하는 수식이 이상함. $\frac{v\cdot q}{|q|_2}$는 스칼라 값이 되기에 수식 대로라면 엣지 임베딩 벡터에 스칼라를 빼는 형태가 되기 때문.
- 실제 깃허브 코드에서 (database/chromaDB.py) 수식이 구현되어 있지만, 논문에 명시된 내용과 다름. 수식에 대해선 추가 확인이 필요
📕 Efficient Subgraph Expansion via Memory Replay
최초로 탐색했던 노드와 엣지에 대해서는 불필요하게 발생하는 LLM call을 줄여야 한다. 따라서 비슷하거나 같은 쿼리가 들어오면 바로 LLM call을 통해 정답을 찾지 않고, 노드 간의 연관성(relevance metric)에 따라 노드를 먼저 탐색하는 방식을 채택한다.
만약, 연관성에 따라 노드를 탐색해도 정보가 충분하지 않다고 LLM이 판단하면, 위의 LLM-Guided Graph Traversal 과정을 시작한다.
노드간의 연관성은 노드 간의 의미적 연관성, 쿼리를 만족하는 것과 엣지 탐색 간의 alignment 이 두 가지 요소를 고려하여 결정된다. (아까 memorize했던 엣지 임베딩이 여기서 사용되는 것이다!)
\[w_{N_{from},N_{to}}=\alpha\cdot\text{sim}\big(\text{emb}(N_{from}),\text{emb}(N_{to})\big)+(1-\alpha)\cdot\frac{\text{emb}(q)\cdot v_{N_{from},N_{to}}}{\|\text{emb}(q)\|}\]- $N_{from}$ : 현재 노드
- $N_{to}$ : 방문하지 않은 $N_{from}$의 이웃 노드
- $\alpha$ : 하이퍼파라미터
- $q,v$ : 각 쿼리 임베딩, 엣지 임베딩
- $\text{emb}(\cdot)$ : 임베딩 함수
- $w_{N_{from},N_{to}}$ : $N_{from}$ 와 $N_{to}$ 간의 연관성
비슷한 쿼리가 들어올 때, 효과적으로 Memorize 할 수 있는지 이론적인 분석이 포함되어 있다. 자세한 내용은 논문을 참고할 것 (Sec. 4 Theoretical Analysis, Appendix F 참고)
📊 Experiments
본 논문에는 LooGLE (LooGLE: Can Long-Context Language Models Understand Long Contexts? (Li et al., ACL 2024)) 데이터셋이라는 특수 데이터셋을 사용했는데, LLM의 장문 텍스트 이해와 추론 능력을 평가하기 위한 벤치마크이다. 해당 데이터셋은 장기 의존성(Long-Dependency) QA 벤치마킹을 위해 사용되었다.
Accuracy는 GPT-4o를 judge로 사용하여 측정하였고, 비용 효율성 평가를 위해 하나의 쿼리당 소비된 평균 토큰 수를 기준으로 잡았다.
Backbone 모델은 GPT-4o-mini, Deepseek-V3 이다.
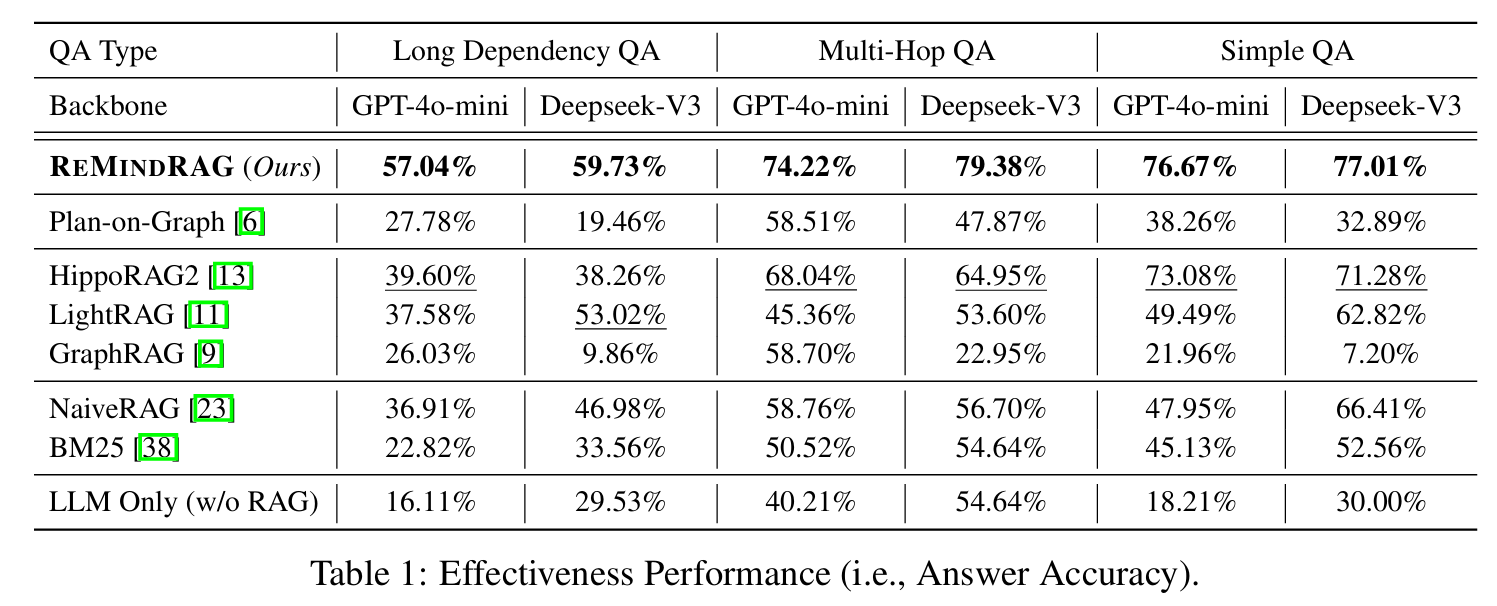
본 논문에서는 Memorization 성능 확인을 위해 쿼리를 따로 구분하여 실험을 진행하였다. 구분 기준은 아래를 참고할 것
- Same Query: 똑같은 쿼리
-
Similar Query: 다른 표현을 사용하나, 의미적으로는 같은 쿼리

-
Different Query: 비슷한 문장 구조를 가지지만, 의미적으로 아예 다른 쿼리

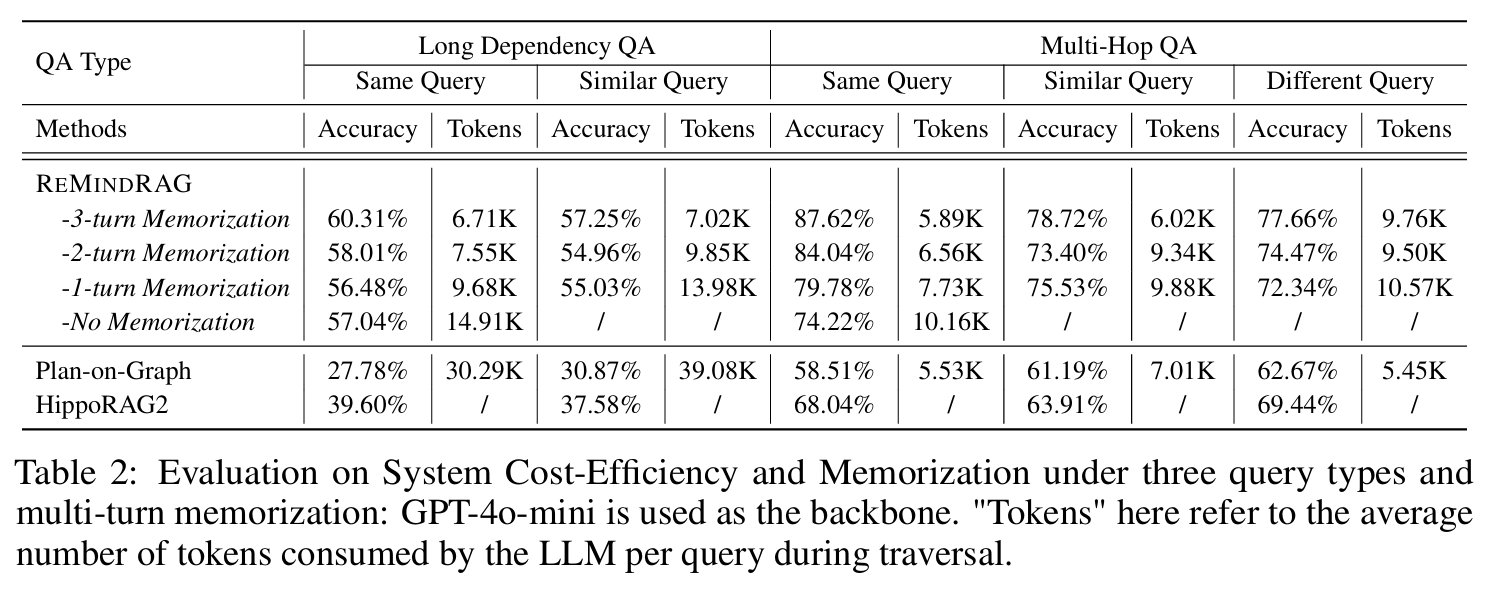
- Memorization을 반복할수록 Accuracy가 상승하고, 소비된 token 수가 감소한다. 이는 Memory Replay가 제 역할을 잘 수행했음을 의미한다.
- Different Query에서도 Memoriztion을 진행할수록 유의미한 성능 향상을 보였다.

- 쿼리를 교차하여 입력한 상황에서 기억 충돌 여부 확인 실험
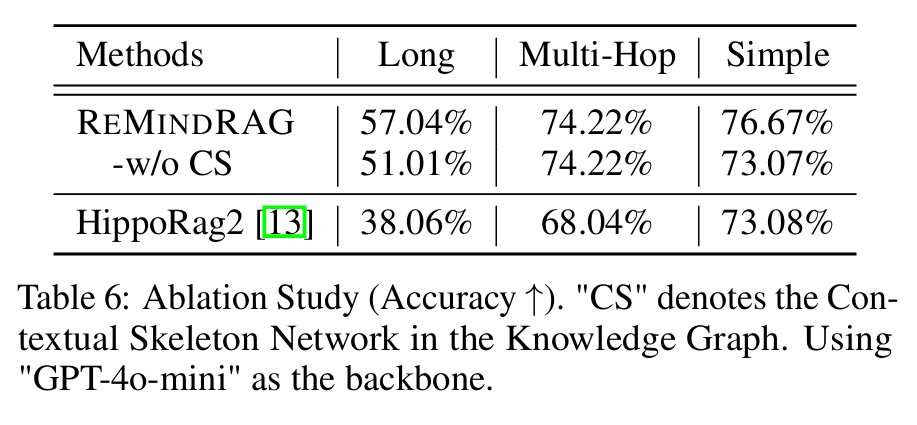
- 맨 처음에 소개한 Contextual Skeleton Network 구조에 대한 ablation study
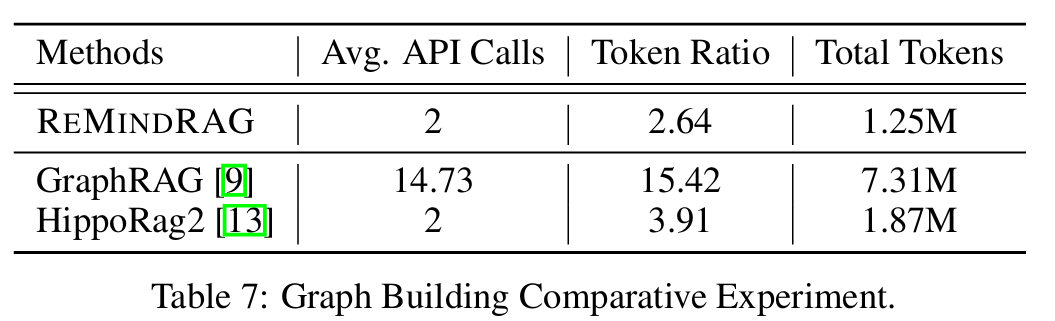
- 그래프 구축에 대한 cost efficiency 측정
💡 Conclusion
- node exploration/exploitation, memory replay를 활용해 그래프를 탐색하는 novel approach 제안
- LLM의 탐색 경험을 효과적으로 기억함을 보임
🛑 Limitations
- Cold-start: 초기에 서브 그래프를 확장하기 위해 어쩔 수 없이 LLM을 여러 번 호출해야 한다. 특히, 아예 다른 쿼리들이 들어오면 그 단점이 더 부각된다.
- 문서 양이 커질수록 KG 구축에서 많은 자원과 시간이 소요된다.