DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (GRPO)
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (GRPO)
작성자: 김두영
날짜: 2026-03-26
논문 이름: DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
논문 정보: arXiv 2024
-
Introduction
DeepSeek에서 수학 도메인을 타겟으로 새로운 모델 DeepSeekMath 공개. DeepSeekMath는 기본적인 LLM의 학습 방식인 Pretraining + Instruction Tuning (SFT) 구조에서 Math Domain Pretraining과 RL을 추가함.
여러가지 실험을 통해서 고품질 수학 및 코드 도메인에서의 추가 Pretraining이 in-domain 및 out-domain 성능을 올릴 수 있음을 보임.
추가적으로 기존의 LLM에 강화학습을 도입하는 과정에서 발생하는 다양한 문제를 해결할 수 있는 GRPO 알고리즘을 제안.
- Preliminary
-
Proximal Policy Optimization (PPO)
PPO는 기존의 TRPO의 안정성 및 데이터 효율성을 유지하면서도 KL divergence 제약 조건으로 인한 문제들 (연산량 및 제한된 모델에서만 적용 가능함)을 해결함.
\[\begin{aligned} r_t(\theta) &= \frac{\pi_{\theta}(a_t|s_t)}{\pi_{old}(a_t|s_t)} \\ \mathcal{J}_{PPO} &= \mathbb{E}_{t} \left[ \min(r_t(\theta)\tilde{A}_{i,t}, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)\tilde{A}_{i,t}) \right] \end{aligned}\]
TRPO는 KL divergence가 특정 임계값 이상으로 벌어지지 않도록 학습을 제안하는 방식으로, 데이터를 샘플링한 모델과 현재 모델의 분포 차이를 제한함.
이를 통해서 신뢰 가능한 영역에서의 강화학습을 수행함.
이 과정에서 KL divergence를 계산하기 위해 필요한 연산량 및 모델 구조 제약 (dropout과 같이 deterministic 하지 않은 요소들)등의 문제가 있었으며, PPO는 간단한 연산만으로 데이터를 샘플링했던 모델과 현재 모델의 분포 차이가 너무 커지는 것을 방지함. (min + clipping)PPO는 모델이 학습할 시그널 Advantage를 계산하기 위해 Value Model (or Value Network)를 사용함.
\[\tilde A_{i,t}=\delta_t+(\gamma\lambda)\delta_{t+1}+...+(\gamma\lambda)^{T-t+1}\delta_{T-1} \newline \delta_t=r_t+\gamma V(s_{t+1})-V(s_{t})\]
Value Model은 각 action (선택된 다음 단어)에 대해 발생한 reward 값과 두 state의 value 차이를 기반으로 Advantage를 추정함.
Value Model을 사용하기 때문에 학습하는 과정에서 더 많은 Cost가 필요함. (일반적으로 Value Model과 Policy Model은 비슷한 크기 및 구조의 모델을 사용) 또한 LLM에서의 reward 구조가 Value Model의 수렴에 어렵다는 문제가 있음.
일반적으로 LLM은 긴 추론 + 예측 답의 형식으로 output을 생성함. 이때 reward는 예측된 답이 정답과 일치하는 경우 발생.
따라서 대부분의 생성된 token은 reward가 0이고, 생성 결과의 마지막 소수의 token만 reward를 받음.
sparse한 reward를 기반으로 전체적인 추론 과정에 대해서 value 값을 추정해 학습하는 것은 value model의 학습을 어렵게 만듬
-
-
Method
GRPO에서는 LLM에서 Policy Optimization 방법을 적용하는 것이 어려운 이유를 Value Model의 한계로 보며, Value Model 없이 Advantage를 계산하는 방법을 제안함.
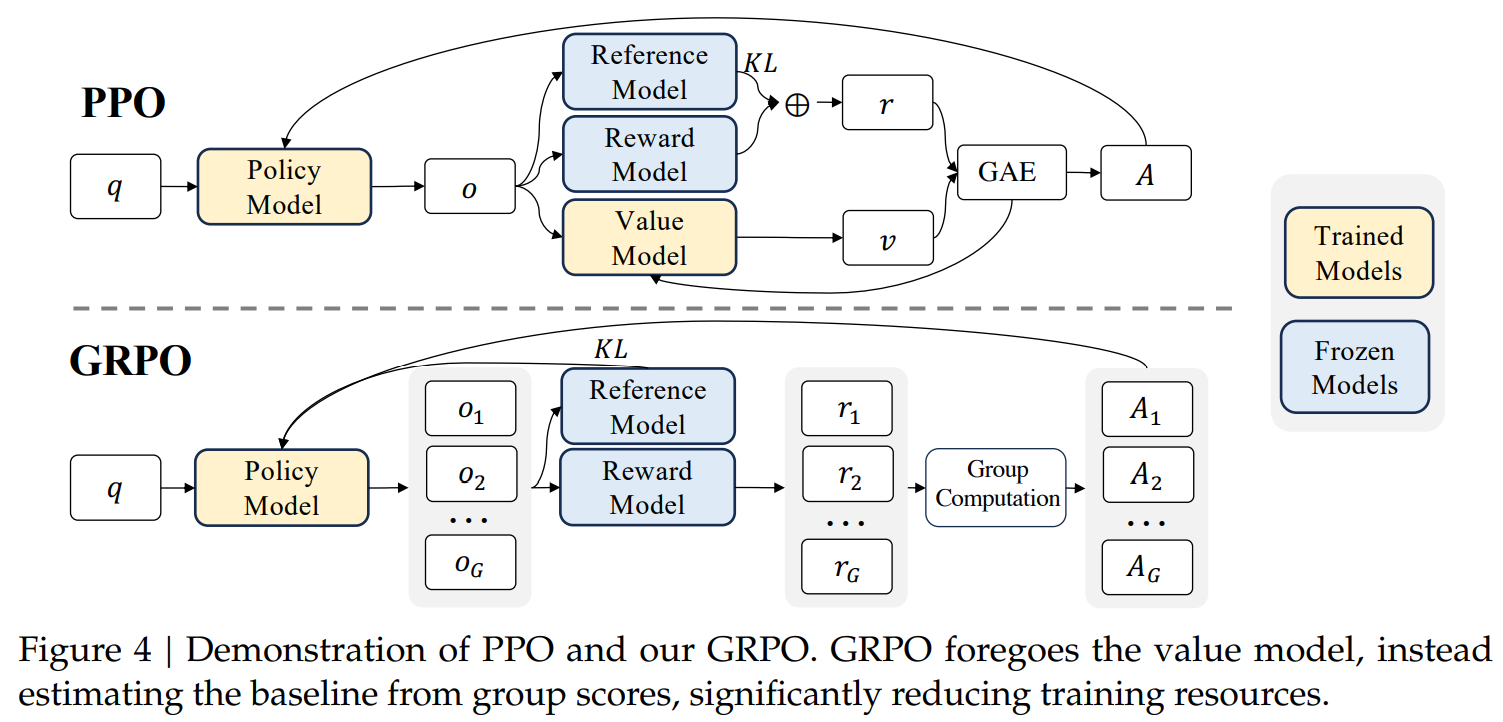
GRPO의 메인 아이디어는 하나의 input 데이터에 대해서 G개의 output sample들을 만들고, 각각의 리워드를 정규화하여 advantage로 사용한다는 것임.
\[\tilde A_{i,t} = \frac{r_i-\mathsf{mean}(\{r_i\}_{i=0}^G)}{\mathsf{std}(\{r_i\}_{i=0}^G)}\]
이를 통해 Value Model 없이 advantage를 계산할 수 있음. 계산된 advantage는 모든 token에 동일하게 적용함. (기존 강화학습의 $\gamma$와 같은 step에 따른 discount 적용 X)최종적으로 GRPO의 Objective Function의 형태는 다음과 같음.
\[\mathcal{J}_{GRPO}=\mathbb{E}_{q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{old}}(O|q)} \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \{\mathsf{min} [r_t(\theta) \tilde A_{i,t}, \mathsf{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)]-\beta \mathbb{D}_{KL}[\pi_{\theta}||\pi_{ref}]\}\]
여기서 KL divergence term의 경우 사용하지 않는 경우도 많음. (논문에서는 기존 연구들에서 reward에 KL divergence term을 넣는 경우가 있는데, 이것이 reward signal을 왜곡시킬 위험이 있고, 따라서 이를 reward와 분리했다고 주장)
- Experiments
-
수학 및 코드 코퍼스에서 사전학습의 필요성
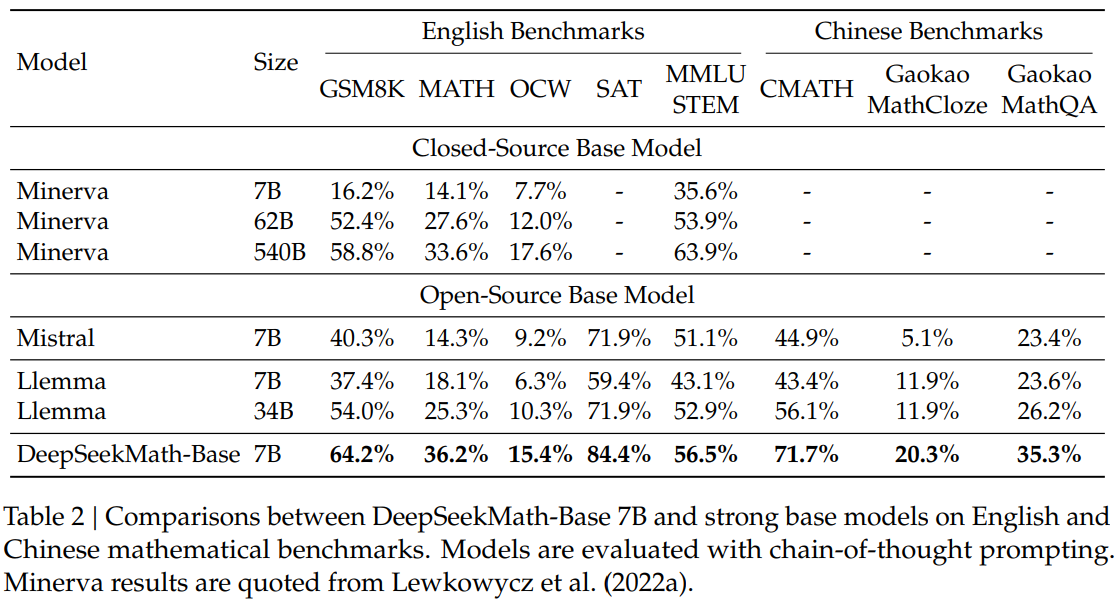
사전학습 후의 성능을 다른 Base 모델과 비교한 결과 유사한 또는 더 큰 모델보다 다양한 벤치마크에서 높은 성능을 보임. (Table 1, 6, 7에서 각각 구축한 수학 코퍼스의 품질 및 사전 학습 방식에 따른 성능을 보고함)
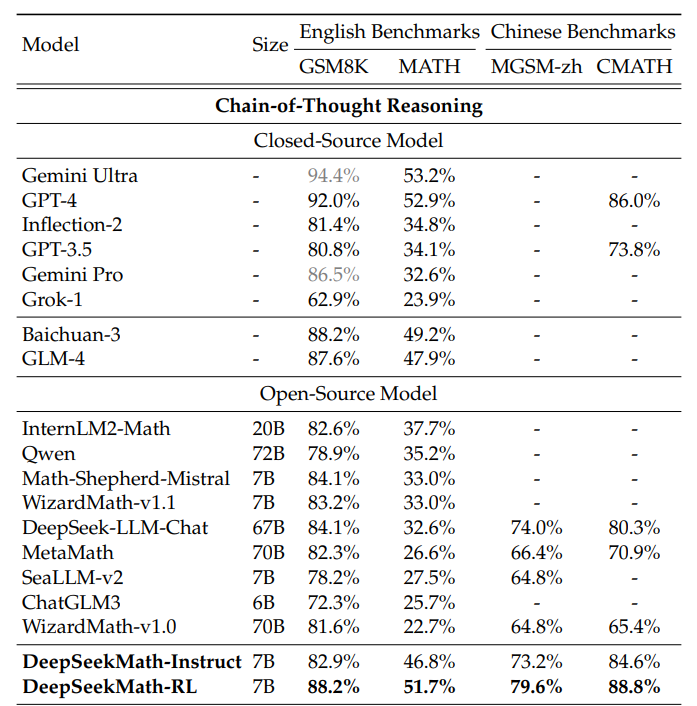
- GRPO의 성능
-
RL 분석 1
Rejection Sampling Fine-tuning과 비교 (RFT): RFT는 강화학습과 유사하게 여러 샘플을 생성한 후 정답을 맞춘 시퀀스만 SFT처럼 학습하는 방법. (각 시퀀스에 대한 가중치가 일정하며, negative 샘플은 학습하지 않는다는것이 GRPO의 차이) RTF와 GRPO의 차이를 보면, 성능 차이가 꽤 많이 나는 것을 확인할 수 있음.
이는 학습 과정에서 negative 샘플들의 확률 값을 낮추는 것 또한 유의미한 학습 signal임을 보임.OS (정답 유무로만 reward) vs PS (풀이과정에 reward): OS는 정답을 맞췄는지 유무로만 reward를 부여하는 방식이고, PS는 풀이 과정에서 부분적인 reward가 발생할 수 있는 환경임.
PS가 더 높은 성능을 달성하는 것으로 보아 추론 과정에서 가치가 있는 추론 과정에 대해서 추가적인 reward를 부여하는 것이 더 세밀한 reward signal을 제공하여 성능 향상에 도움을 줌 (다만 PS 방식은 더 많은 학습 cost를 필요로 함)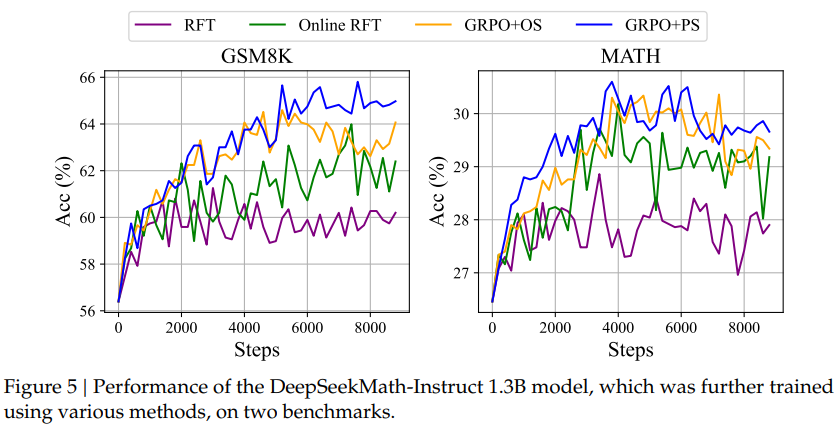
Offline RL vs Online RL: Iterative하게 GRPO를 학습시키는 과정에서 Reward 모델을 업데이트 하는 것이 중요할 수 있음을 보임 (보라-노란 그래프가 공존하는 구간 / 노란-초록 그래프가 공존하는 구간).
이는 Reward 모델이 특정 Policy에 대한 reward를 추정하는 모델이기 때문에, Policy가 업데이트 되는 과정에서 강화학습이 불확실한 정보를 기반으로 업데이트를 수행할 수 있음을 의미함.
따라서 가장 이상적인 환경을 위해서는 업데이트된 Policy의 기대 reward를 정확하게 추정할 수 있도록 Online RL 환경이 되어야 함을 시사 (다만 이것 역시 학습 cost가 큼)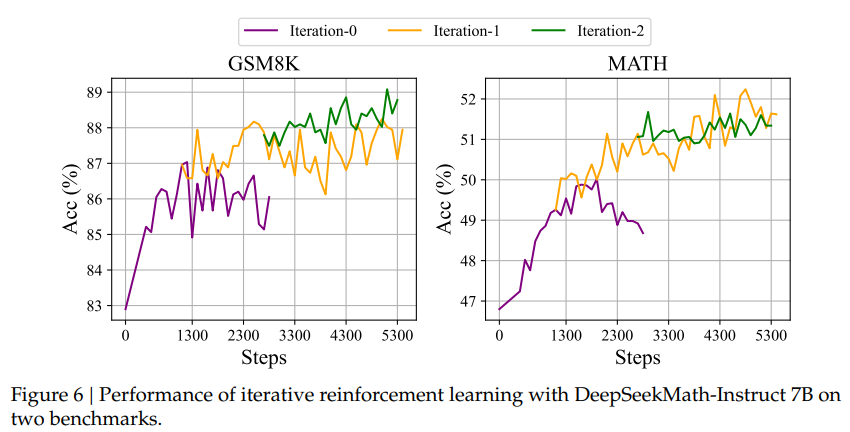
-
RL 분석 2
강화학습은 어떤 것을 학습하는가에 대한 분석으로 K개 중에서 답이 있는지 여부 (Pass@K)와 K개 중에서 가장 major한 답의 정답 여부 (Maj@K)를 비교함. 그 결과 강화학습은 두 지표 모두 개선하는 것을 확인할 수 있음. 다만 강화학습된 모델과 Instruct Tuning된 모델에서의 성능 차이가 Pass@K에서 거의 없고 Maj@K에서 많은 차이가 있는 것을 확인할 수 있음. 이는 모델이 못푸는 문제를 잘 푸는 것이 아니라, 풀 수 있는 문제에서 올바른 풀이의 확률을 더 증가시키는 것으로 보인다고 주장함.
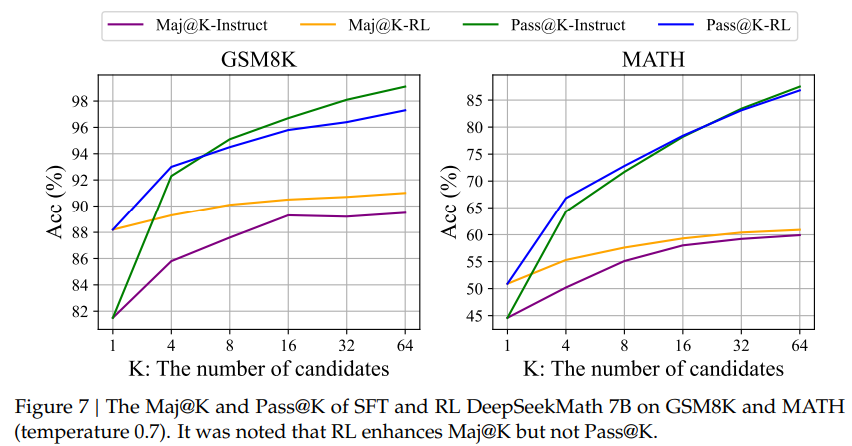
-
- Conclusion
- 논리적 추론 성능을 위해서 수학 및 코드 도메인에서의 추가적인 사전학습의 필요성을 보임
- LLM에서 잘 동작할 수 있도록 Value Model을 제거한 GRPO 알고리즘을 제안함
- 강화학습에 대한 다양한 분석을 제공하였으며, 특히 RL은 모델 자체의 추론 능력을 강화한다기보다 모델이 생성할 수 있는 답안에서의 확률을 재할당한다는 관점을 제시함.