Dense Passage Retrieval for Open-Domain Question Answering
Dense Passage Retrieval for Open-Domain Question Answering
URL: https://arxiv.org/abs/2004.04906
Difficulty: MEDIUM
Progress: 완료
Study Date: 2024/07/23
Summary: DPR paper, In-batch negative sampling 제안
Contribution
-
적절한 학습 설정만 갖춘다면, 기존의 Query-Passage 쌍으로 Query 및 Passage Encoder를 fine-tuning하는 것만으로도 BM25의 성능을 크게 뛰어넘을 수 있음을 증명함.
-
Retriever의 검색 정밀도 향상이 최종적인 End-to-End QA 정확도 향상으로 직결됨을 검증함.
Introduction
Open-domain QA 시스템은 일반적으로 두 가지 프레임워크로 구성됨.
- Context Retriever: 방대한 문서 코퍼스에서 질문과 관련된 문서 추출
- Machine Reader: 추출된 문서에서 정답 도출
Open domain QA에서는 이전까지 주로 TF-IDF 또는 BM25와 같은 Sparse Retriever(희소 검색기)를 사용해왔음.
반면, Dense retriever(밀집 검색기)는 학습 가능하고, 의미론적 거리를 기반으로 관련 벡터를 찾을 수 있다는 장점이 있음.
ex) bad guy ⇒ villain
그러나 이전에는 좋은 dense vector representation을 학습하기 위해 막대한 pre-training 비용이 들고, Context-encoder가 QA 쌍으로 직접 학습되지 않아 최적의 결과를 내지 못한다는 편견이 있었음.
Main Question
과연 대규모 Pre-training 없이, 오직 Query-Passage 쌍만 사용해서 밀집 임베딩 모델을 더 잘 학습할 수 있을까?
Dense Passage Retriever (DPR) Methodology
Encoders & Inference
-
Encoders
bert-base-uncased(d=768)모델을 사용하며, 최종 표현으로 [CLS] 토큰의 벡터를 사용함. -
Similarity
Query와 Passage 임베딩 간의 내적으로 유사도를 계산함.
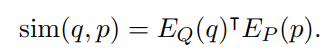
-
Inference
추론 시 Passage Encoder $E_P$를 모든 Passage에 적용하여 오프라인으로 임베딩한 후, FAISS를 통해 인덱싱함.
이후 주어진 Query $q$에 대해 Top-K passage를 검색함.
Training Objective
학습 데이터 $D$가 하나의 질문$(q)$, 하나의 관련 있는 Positive Passage$(p^+)$, 그리고 $n$개의 관련 없는 Negative Passage$(p^-)$로 구성되어 있다고 가정할 때,
다음과 같은 NLL(Negative Log-Likelihood) Loss로 학습을 진행함.
-
Training
$D={<q_i, p_i^+, p_{i,1}^-, p_{i,2}^-, …, p_{i,n}^->}_{i=1}^{m}$
$L(q_i, p_i^+, p_{i,1}^-, p_{i,2}^-, …, p_{i,n}^-)=-log\dfrac{e^{sim}(q_i,p_i^+)}{e^{sim}(q_i,p_i^+) + \Sigma_{j=1}^{n}e^{sim}(q_i,p_{i,j}^-)}$
Positive and Negative passages
Retrieval 학습에서 Positive Passage는 비교적 찾기 쉬운 반면, 수많은 코퍼스 속에서 어떤 Negative Passage를 선택할 것인가가 성능을 좌우함.
논문에서는 세 가지 Negative 샘플링 방법을 고려함.
1) Random: 코퍼스에서 무작위 추출
2) BM25 (Hard Negative): 질문의 토큰은 많이 포함하고 있지만, 정답은 포함하지 않는 Passage
3) Gold: 다른 질문과 짝지어진 Positive Passage들
In-batch Negative Training (Training Strategy) 🌟
Mini-batch 내에 $B$개의 질문이 있다고 가정하고, Query 임베딩 행렬 $Q$와 Passage 임베딩 행렬 $P$ 크기가 모두 ($B \times d$)일 때, 유사도 행렬 $\mathbf{S=QP^T}$는 ($B \times B$)행렬이 됨.
이 경우, 대각선 요소는은 Positive 쌍이 되고, 비대각선 요소는 Negative 쌍으로 활용됨.
이러한 방법은 Dual Encoder 설정에서 매우 효율적이고 강력한 학습 전략임.
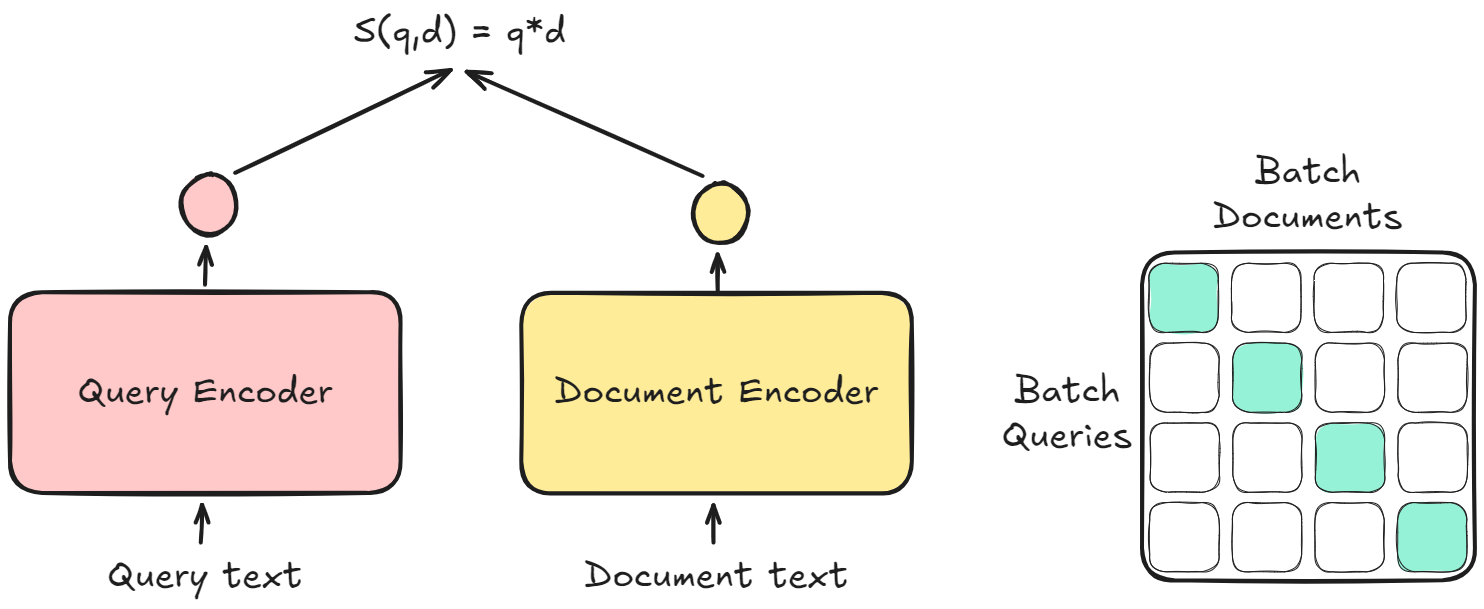
In-Batch Negative Training illustration
Experiments
- Datasets
- Natural Questions (NQ)
- TriviaQA
- WebQuestions (WQ)
- CuratedTREC (TREC)
-
SQuAD v1.1 - 보통 OpenQA에는 적합하지 않지만, 사용함
(많은 질문들이 context와의 맥락과 관계가 없기 때문)
- Configurations
- Batch size = 128
- Epochs = 40 for large (NQ, TriviaQA, SQuAD), 100 for small (WQ, TREC)
- Optimizer = Adam (learning_rate = 1e-5, scheduling=linear, warm_up=True, dropout_rate=0.1)
Main Results
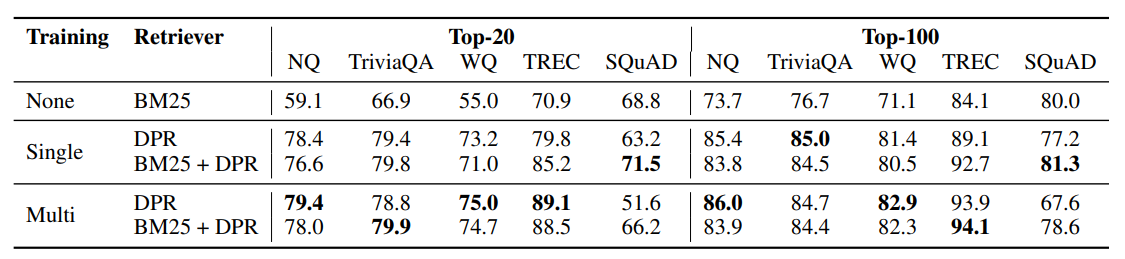
일반적으로 SQuAD를 제외한 모든 데이터셋에서 DPR이 BM25의 성능을 큰 격차로 압도하는 모습을 보임.
특히 검색된 문서 수가 작을 때 (k=20) 그 차이가 더욱 두드러짐.
BM25와 DPR을 선형 결합했을 때 가장 성능이 좋았음.
Ablation Study
Sample Efficiency
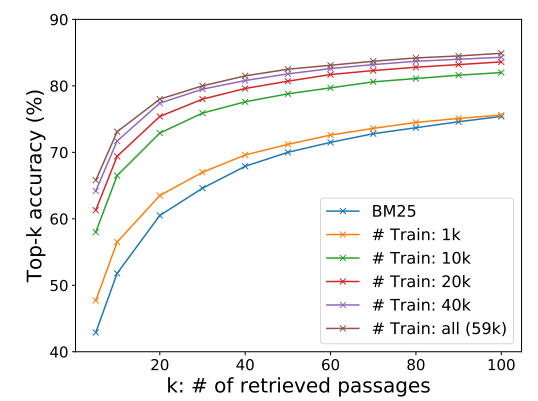
-
Training set을 1K만 해도 BM25를 능가하고, 10K부터는 큰 차이가 있음.
⇒ 소량의 데이터셋만으로도 큰 성능 향상을 불러올 수 있음을 시사함.
-
이후에도 점진적으로 성능이 개선되는 것을 볼 수 있음
In-batch Negative Training & Hard Negatives
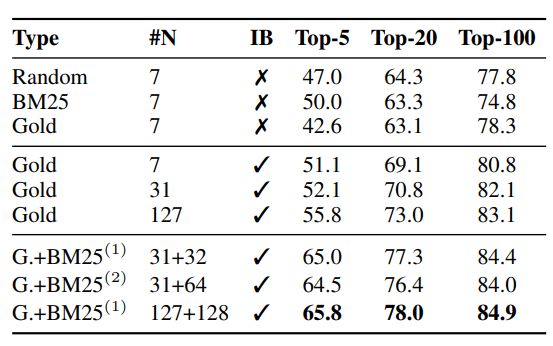
-
표준적인 1-of-N 세팅보다 (positive = 1, negative=N) In-batch 방식을 사용할 때 N을 늘릴수록 유의미한 성능 향상을 보임.
-
여기에 BM25 방식의 Hard Negative 샘플을 추가했을 때, 특히 k가 작을수록 전체적인 성능 향상 폭이 매우 컸음.
Impact of gold passages
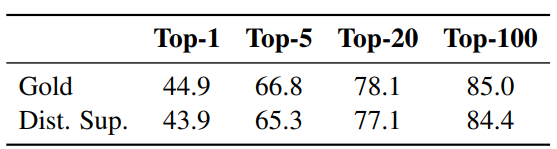
- 명시적인 Gold passage가 없는 경우, 정답(Answer)을 포함하고 있는 최상위 BM25 passage를 사용하였을 때 정확도 하락은 단 1 point에 불과했음.
Similarity and Loss
- L2 Loss나 Triplet Loss보다 일반적으로 Dot Product + NLL Loss 구조가 가장 우수한 결과를 보임.
Cross-dataset Generalization
- 추가적인 Fine-tuning 없이, NQ 데이터셋으로만 학습한 모델을 WQ나 TREC에 테스트했을 때 Top-20 정확도가 3~5 point 가량 낮아졌으나, 여전히 BM25보다 높은 성능을 기록함. (Zero-shot 환경에서도 강력한 일반화 성능 입증)
Follow-up Study & Conclusion
-
Follow-up: Hard Negative를 더 적극적으로 활용하는 아이디어 확장이 가능하며, BART나 T5 같은 Generation Model과 DPR을 결합한 연구(예: FiD, RAG)로 발전할 수 있음.
-
Conclusion: Dense Retrieval은 Open-domain QA에서 전통적인 Sparse Retrieval(BM25)을 충분히 대체할 수 있으며, 복잡한 모델 프레임워크나 복잡한 유사도 측정 함수 없이도, 본 논문에서 제시한 단순화된 구조와 적절한 학습 전략만으로 훌륭한 성능을 달성할 수 있음을 입증함.