Ask Optimal Questions: Aligning Large Language Models with Retriever’s Preference in Conversational Search
Ask Optimal Questions: Aligning Large Language Models with Retriever’s Preference in Conversational Search
이 논문은 Conversational Search에서 적합한 문서를 보다 잘 불러오기 위해 사용자 질의, query를 optimization하는 방법에 관한 논문이다.
Background
Conversational Search는 대화의 형태로 정보 검색을 수행하는 작업으로 이는 단순히 키워드를 넘어 문맥을 이해하고 질문 간의 관계를 파악하는 능력이 요구된다. 이러한 능력을 충족시키기 위해 사용자가 입력한 query를 재구성하는 과정이 필요하다.
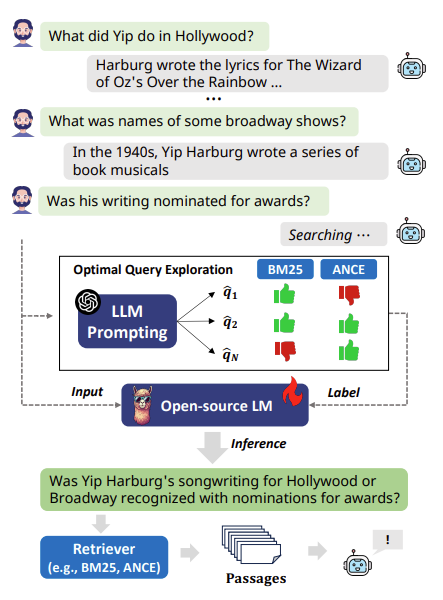
Figure 1.
Figure 1을 보면 마지막 질의 ‘Was his writing nominated for awards?’는 맥락의 파악을 통해 his writing이 무엇을 의미하는지를 파악하여 ‘Was Yip Harburg’s songwriting for Hollywood or Broadway recognized with nominations for awards?’로 재구성 수 있다.
이렇게 쿼리에서 ommision, ambiguity, coreference 문제를 해결하고 재구성한 쿼리를 rewrite라고 한다. 그리고 retrieval systems에 사용되기 전에 rewrite한다 하여 이러한 접근법을 rewrite-then-retrieve라고 한다.
지금까지의 rewrite-then-retrieve에 대한 연구는 주로 human rewrite를 라벨로 하여 학습하였다. human rewrite는 맥락 상 어색한 문제들을 해결할 수는 있지만 이는 검색 성능을 고려하지는 않는다. 본 논문은 검색 성능까지 고려하기 위해 retriever이 선호도를 반영하여 쿼리를 rewrite하는 방법을 제안한다.
Retriever’s Preference Optimization (RETPO)
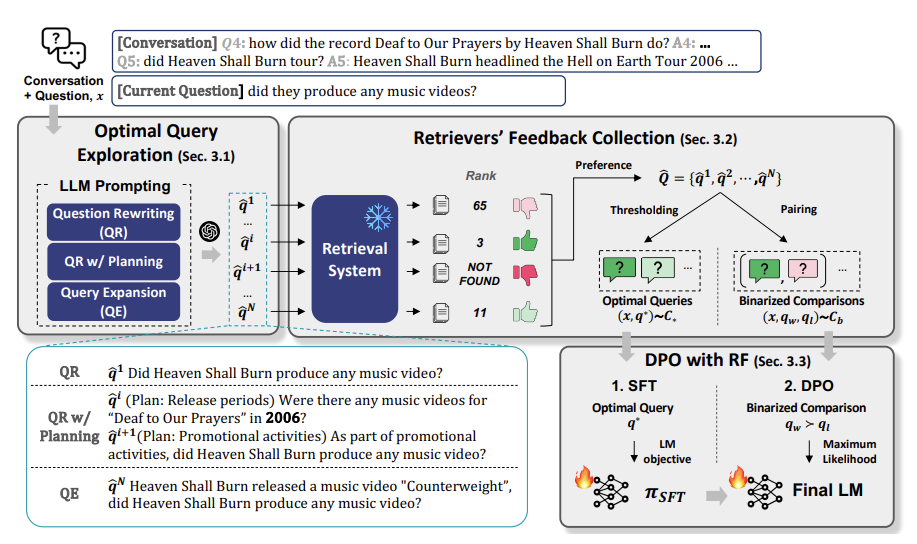
Figure 2.
Optimal Query Exploration
query를 retriever의 선호도를 고려하여 재구성하기 위에 다양한 프롬프트 기법을 활용하여 rewrite 후보들을 생성한다. 이 optimal query exploration의 목표는 optimal query를 찾기 위함이다. 그렇다면 optimal query란 무엇인가하면 아래와 같다.
\[q^*=\underset{q}{\mathrm{argmax}}\,{Eval(Ret(q), d^+)}\]말로 설명하자면, optimal query란 특정 검색 시스템이 정답 passage인 gold passage, $d^+$를 가장 높은 score로 측정하게하는 query를 말한다.
query rewrite를 할 때, ‘GPT-4’를 프롬프팅하여 생성된 데이터셋으로 ‘Lamma2-7b’를 학습시켜 사용한다.
\[H_{<t}=\{q_i, a_i\}^{t-1}_{i=1}, x=Concat(H_{<t}, q_t)\]question rewrite를 위한 모델의 input은 위처럼 과거 대화 histroy와 현재 question을 concat한 것으로 question rewrite가 생성되면 해당 rewrite로 관련 문서를 불러온다.
-
Question Rewriting
Question Rewriting은 질문에서 coreference(대명사)나 ellipses(생략된 표현)를 문맥을 고려하여 재구성하도록 프롬프팅 하는 것이다.
Figure 2를 보면 ‘did they produce any music videos?’ 라는 질의를 ‘Did Heaven Shall Burn produce any music video?’로 재구성하여 coreference 문제를 해결하였음을 알 수 있다.
-
QR with Planning
QR with Planning은 LLM에게 질문의 중요한 부분과 목적을 정확히 정의하도록 하는 것이다. Chain-of-Thought에서 영감을 받아 중간 추론 단계를 추가하여 질문이 더 구체적인 목표를 가지도록 설계하였다. 특히 프롬프팅할 때, LLM이 자체적으로 가지고있는 지식이나 제공된 대화 내용에서 관련 정보를 이끌어내도록 유도하였다.
Figure 2를 보면 ‘did they produce any music videos?’ 라는 질의를 ‘(Plan: Release periods) Were there any music videos for “Deaf to Our Prayers” in 2006?’으로 그리고 ‘(Plan: Promotional activities) As part of promotional activities, did Heaven Shall Burn produce any music video?’로 재구성하였다.
Chain-of-Thought란?
CoT는 복잡한 문제를 풀거나 추론을 수행할 때, 단계적인 논리 전개 과정을 명시적으로 생성하도록 설계된 기법이다.
복잡한 문제에 대해 더 정확하고 일관성 있는 답변을 생성하고, 모델이 논리적 추론을 수행했는지 확인할 수 있다는 장점이 있다.
-
Query Expansion
Query Expansion은 LLM이 그럴듯한 답이나 관련 정보를 생성하도록(external knowledge 없이) 하여 이 pseudo-answer를 self-contained rewrite에 추가하는 것이다. 만일 human rewrite도 사용가능하다면 마찬가지로 추가한다.
Figure 2를 보면 ‘did they produce any music videos?’ 라는 질의를 ‘Heaven Shall Burn released a music video “Counterweight”, did Heaven Shall Burn produce any music video?’로 재구성하여 Counterweight라는 pseudo-answer를 추가하였다.
이 과정은 gold passage와 query 간의 keyword overlab을 유도하여 retrieval system에게 더 정보를 준다.
이 3가지 프롬프팅 방법은 각각 rewrite를 한번에 5~10개씩 special token으로 구분하여 생성한다. 이렇게 한번에 생성하면 LLM이 중복 쿼리를 생성하는 것을 방지하여 더 다양한 쿼리를 얻어 optimal query를 얻을 가능성이 더 높아진다.
Retrievers’ Feedback Collection
optimal query exploration을 통해 수집된 질의를 BM25(Sparse Retriever)와 ANCE(Dense Retriever)로 평가하여 다음과 같이 데이터셋을 구성하였다. 이를 RF COLLECTION이라 한다.
평가는 검색된 passage들 중 gold passage의 순위로 평가한다.
-
최적 질의 집합 ($C_*$)구축 (For supervised fine-tuning)
하나의 query에 대해 상위 5개의 재구성된 질의를 선택하여 구성한다. 즉, gold passage의 순위를 가장 높게 평가한 상위 5개의 질의를 말한다.
이때 상위 5개의 재구성된 질의는 사전에 정의된 기준 순위를 초과하지 않는 경우에만 포함된다. 만일 생성된 모든 질의가 기준을 초과하지 못할 경우, 가장 높은 순위를 가진 질의를 선택한다.
-
이진 비교 집합 ($C_b$) 구축 (For preference optimization)
우선 똑같은 input $x$에 대해 생성된 rewrite candidate로 rank 정렬을 해서 $\hat{Q}={\hat{q}^1,\hat{q}^2,…,\hat{q}^{|\hat{Q}|}}$, ($\hat{q}^1>\hat{q}^2>…>\hat{q}^{|\hat{Q}|}$)를 만든다.
그리고 ${(\hat{q}^j, \hat{q}^k):j<k}$와 같이 중복 없이 랜덤하게 페어를 이루도록 한다. 이 랜덤하게 이루어진 pair 는 $(q_w, q_l)$로 $q_w$는 preferred query가 되고 $q_l$은 dispreferred query가 된다. 이중에서 preferred query가 사전에 정의된 기준 순위를 초과하지 않는 경우는 걸러낸다.
Direct Preference Optimization with Retrievers’ Feedback
이제 구축된 RF COLLECTION으로 ‘Lamma2-7b’를 학습시키는 방법에 대해서 설명하겠다.
-
Supervised Fine-Tuning (SFT)
우선 SFT 과정에서는 모델은 질문을 효과적으로 재구성하도록, 그리고 Query Expansion에서 pseudo-answers를 생성하는 능력을 강화하도록 학습된다.
- 대화 맥락에서 생성된 ground-truth response를 그대로 복제하도록 학습된다.
-
RF COLLECTION에서 추출한 $C_*$를 사용하여 fine-tuning한다.
LM \(\pi\)는 \(\pi_{SFT}=\underset{\pi}{max}\mathbb{E}_{(x, q^*)\sim C_*}log\,\pi(q^*\mid x)\)가 되도록, 즉, 확률 모델 \(\pi\)가 주어진 input \(x\)에 대해 optimal query \(q^*\)를 생성할 확률이 높아지도록 학습한다.
-
Direct Preference Optimization (DPO)
SFT된 모델을 바탕으로 검색 시스템의 선호도를 더 반영하여 학습하도록 DPO 방법(Alignment learning의 일환)으로 추가 학습 시킨다.
Alignment learning이란?
Alignment learning은 ai를 의도한 목표, 선호도 또는 윤리적 원칙에 맞게 조정하는 것을 말한다.
Direct Preference Optimization이란?
강화학습과 같은 학습 시스템에서 직접적인 사용자 또는 정책의 선호를 반영하여 모델을 최적화하는 방법론이다. 전통적인 RL에서는 환경의 보상 함수를 명시적으로 정의해야 하지만, DPO는 보상 대신 선호 데이터를 사용하여 정책을 조정한다.
모델 $\pi_\theta$는 preferred query $q^w$를 dispreferred query $q^l$에 비해 생성할 확률이 높도록 학습한다.
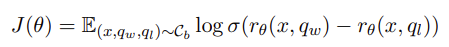
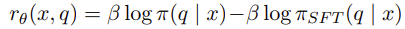
여기서 $r_\theta$는 특정 쿼리 $q$를 SFT 모델과 비교하여 생성할 확률을 나타낸다. $\beta$가 양수일지 음수일지는 안나와있지만 양수라고 했을 때를 생각해보자. $q$가 preferred query $q_w$이고 현재 모델이 SFT 모델보다 개선이 되었다면 $r_\theta$는 양수가 될 것이다. 반대로 $q$가 dispreferred query $q_l$이고 현재 모델이 SFT 모델보다 개선되었다면 $r_\theta$는 음수가 될 것이다.
이 DPO 과정을 통해 모델이 질문을 retriever가 선호하는 방식으로 재구성하도록 학습한다.
Experiment
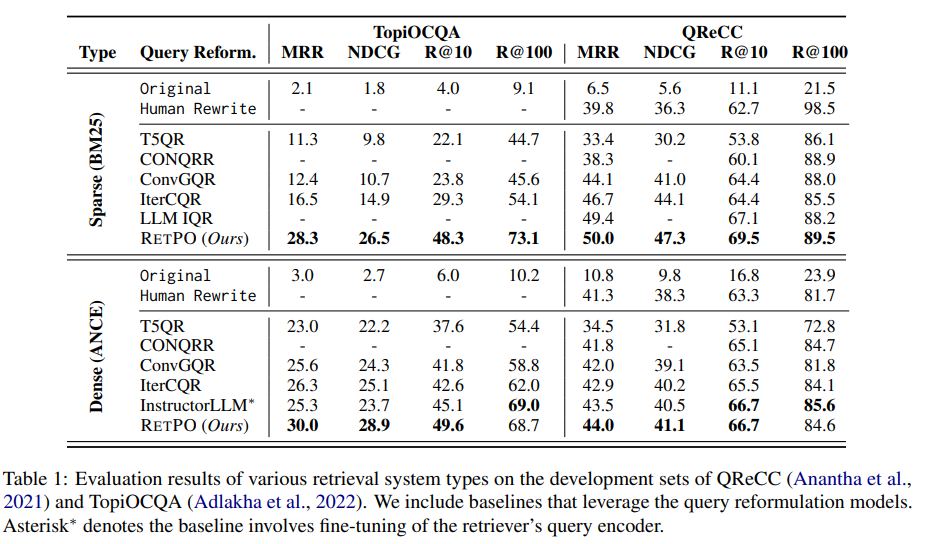
본 논문은 open domain CQA benchmarks인 QReCC와 TopiOCQA dataset에 대해 테스트를 하였다. RF-Collection은 이 데이터셋에 대해 구축되었으며 Retriever들은 해당 데이터셋에 대해 fine-tuning되지 않았다.
위와 같이 TopiOCQA, QReCC 데이터셋 모두에 대해 성능 향상을 보였으며 파라미터 면에서도 효율적이다. 따라서 이를 통해 retriever의 preference를 반영하는 것이 성능 향상에 도움이 된다고 논문에서 주장한다.
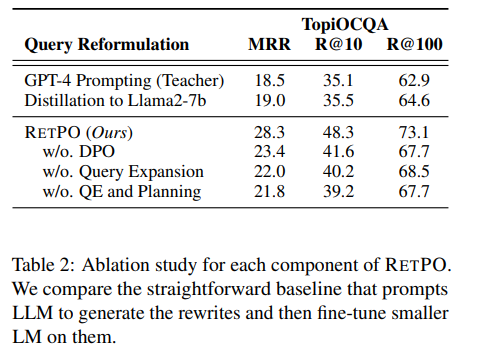
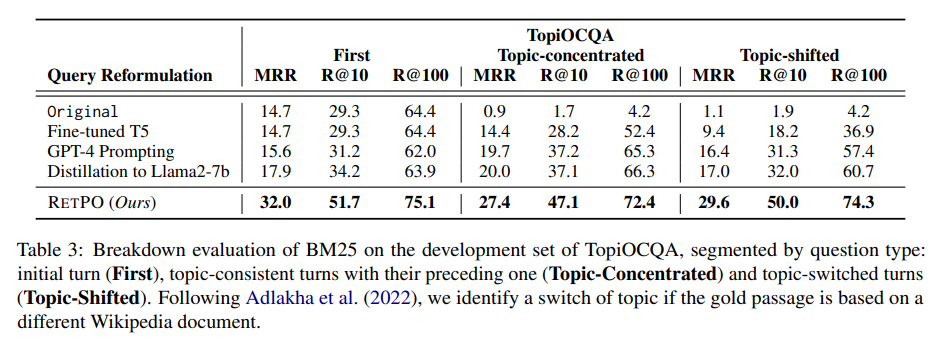
Table 2 는 DPO 학습, Query Expansion, QE and Planning 방식을 없앴을 때, 성능이 하락함을 보여주어 이 방법들이 효과적임을 보여준다.
Table 3 는 RETPO가 주제가 전환될 때, 전환되지 않을 때, 대화 문맥이 필요없는 질문(단일 턴 QA처럼)에서도 성능이 개선됨을 보여준다.
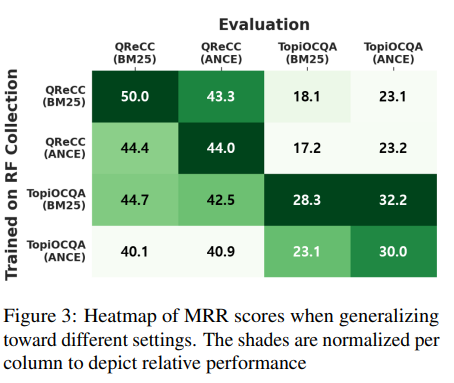
Figure 3.
Figure 3는 데이터셋이나 평가와 학습 데이터 retriever가 다를 때의 능력을 평가한 히트맵이다.
당연하게도 데이터셋과 retriever가 동일할 때, 가장 성능이 높고 TopiOCQA RF-Collection으로 학습된 모델이 QReCC 데이터셋으로 평가해도 성능 감소폭이 적다. 이는 TopiOCQA가 더 복잡한 문제를 제시하는 것으로 보인다.
또한 bm25 retriever로 평가된 RF-Collection으로 학습된 모델이 ANCE 모델로 평가되어도 더 효과적이었다. 이는 bm25가 query expansion과 같은 전략에 더 효과적이기 때문으로 볼 수 있다.
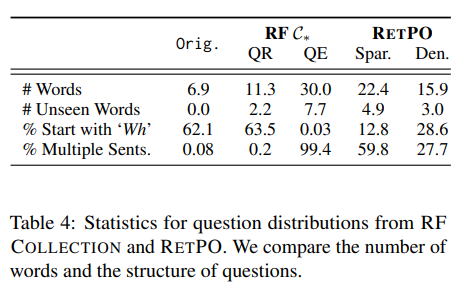
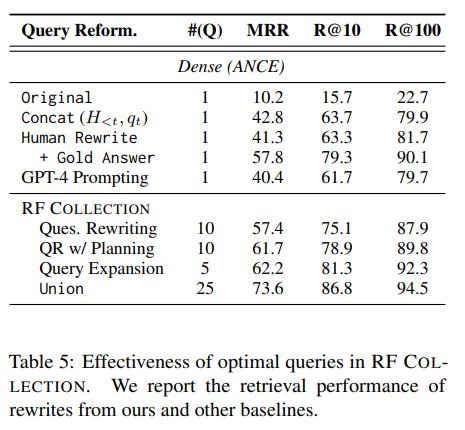
Table 4는 RF-Collection에서 rewrite의 통계적 분석결과를 보여준다. 대충 원래 query보다 2~5배 더 긴 질문을 생성하는 경향이 있다.
Table 5는 다양한 질문 rewrite 전략의 성능을 종합적으로 비교한 결과를 보여준다.
Limitation
- LLM에만 초점을 맞추었다.
교사 모델로
GPT-4를 사용하고GPT-4를 사용하여 생성한 RF-Collection으로 학습하였기 때문에 학습된 모델 자체가GPT-4의 능력에 크게 의존하고 있다. - 고급 retrieval system과의 결합 가능성 bm25와 ANCE라는 비교적 단순한 검색 시스템과 결합하여 사용하여 평가만 하였다. 고급 검색 시스템과 결합하는 것 또한 하나의 방향이다.