Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval
URL: https://arxiv.org/abs/2007.00808
Difficulty: EASY
Progress: 완료
Study Date: 2024/07/30
Summary: ANCE paper
Contribution
- In-batch Negative가 정보력이 약하다는 것을 밝힘.
- ANN(Approximate Nearest Neighbor) 기반 비동기적 대조 학습을 제안하고, 속도가 빠름.
Introduction
Dense Retrieval(DR) 모델을 학습할 때 가장 큰 과제(key challenge)는 어떻게 적절한 오답 문서를 만들 것인지임.
기존의 In-batch Negative 방식은 정보력이 떨어지는 Negative 샘플이 압도적으로 많아 학습의 병목 현상(Learning Bottleneck)을 초래한다.
이는 낮은 기울기 norm과 큰 확률적 기울기 분산으로 이어져 학습에 지나치게 오랜 시간이 걸리게 만듦.
따라서 DR 모델이 제대로 학습되려면 Relevant(정답) 문서와 정보력이 높은 Negative 문서 사이의 간격을 벌리도록 학습해야 하며, Negative를 얼마나 잘 고르는지가 성능의 핵심임.
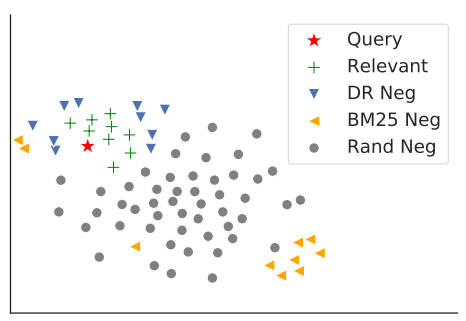
그러나 위의 2차원 T-SNE 시각화에서 나타난 것과 같이 Sparse Model로 가져온 negative는 진짜 어려운 문제를 푸는데 도움이 되지 못함.
Preliminaries
Learning with Negative Sampling
DR에서 중요한 것은 Relevant와 Irrelevant를 잘 구분할 수 있는 표현 공간을 만드는 것. 아래의 목적 함수를 최소화하여 구함.
\[f(q,d)=\text{sim}(g(q;\theta),g(d;\theta))\] \[\theta^{*}=\text{argmin}_{\theta}\Sigma_q \Sigma_{d^+ \in D^+} \Sigma_{d^- \in D^-} l(f(q, d^+), f(q, d^-))\]Convergence Rate and Gradient Norms
효과적인 학습을 위해서는 인스턴스별 기울기 노름(Gradient norm)에 비례하여 Negative 샘플을 추출해야 함.
\[p^*_{d^-}=argmin_{p_{d^-}}Tr(V_{P_{D^-}}(g_{d^-})) \propto \mid \mid\nabla_{\theta_t} l(d^+, d^-)\mid \mid _2\]The problem: Diminishing Gradients of Uninformative Negatives
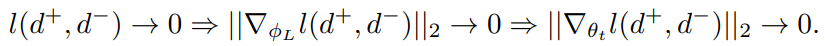
DR 모델 학습의 수렴 속도는 구성된 Negative 샘플이 얼마나 정보가 풍부한지에 달려 있음.
그러나 기존에 많이 쓰이던 In-Batch Negative 방식은 유의미한 Negative를 포함할 가능성이 매우 낮은데, 이는 배치 크기 b와 의미 있는 Negative 집합이 전체 코퍼스 크기에 비해 매우 작기 때문.
(\(\because b << \mid C\mid\ \& \ \mid D^{-*} \mid << \mid C \mid\))
Approximate Nearest Neighbor Noise Contrastive Estimation
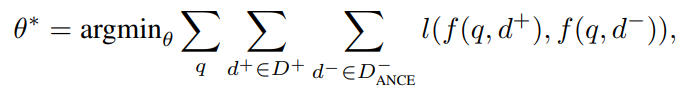
\(D^-_{ANCE}=ANN_{f(p,d)}\), 여기서 ANN은 현재 학습 중인 인코더를 기반으로 가장 유사도가 높게 검색된 문서들을 비동기적으로 선택하여 Hard Negative로 활용함.
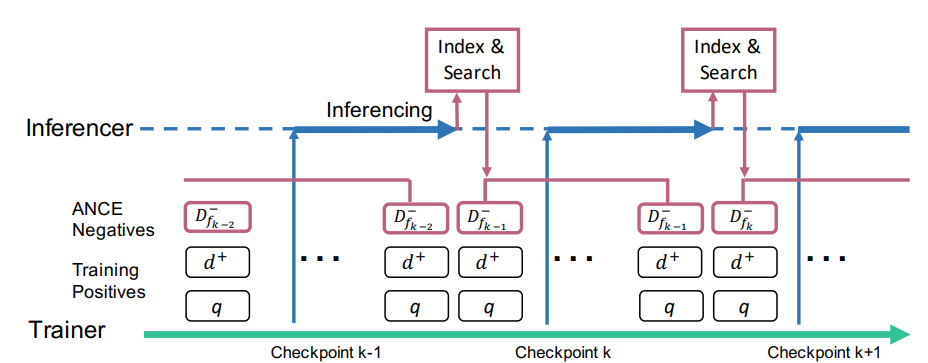
이를 통해 무의미한 샘플 대신, 모델이 헷갈려 하는 유의미한 Negative만을 집중적으로 학습시켜 학습 속도와 성능을 동시에 끌어올림.
Experiments & Results
Negative Sampling
- Random negative sampling
- BM25 Top-100 기반 랜덤 샘플링
- Random과 BM25 Top-100의 1:1 혼합
Encoder
Roberta-base
Dataset
- MSMARCO / TREC-DL
Truncation Strategies
- FirstP: Document의 초반 512 토큰
-
MaxP: Document를 512 토큰의 Passage으로 최대 4개로 나누고,
passage-level 점수를 max-pooling함.
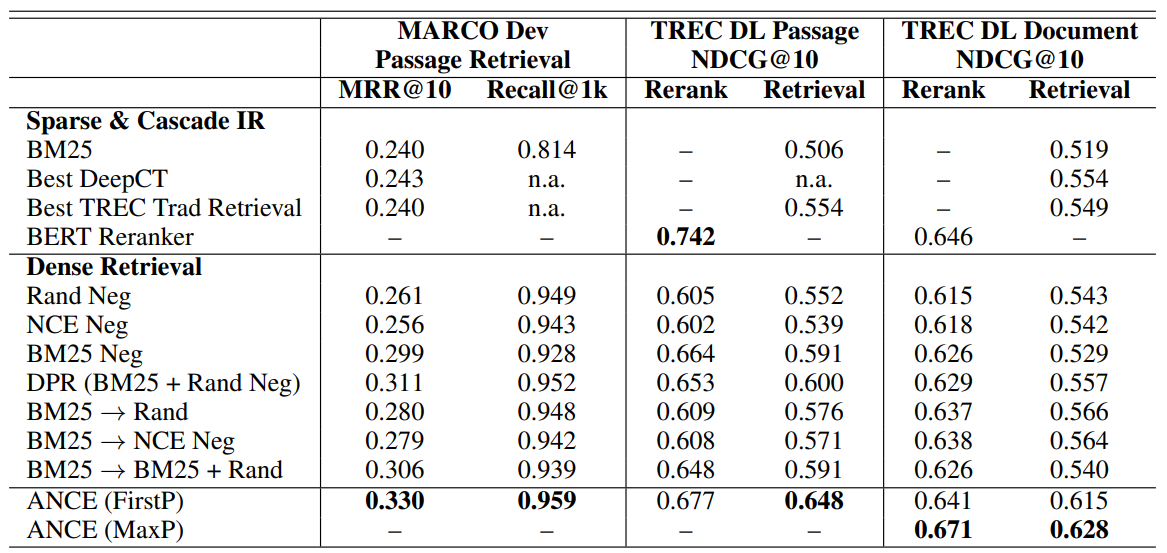
결과적으로 Retrieval Task에서 SOTA를 달성함.
Efficiency of ANCE Search and Training
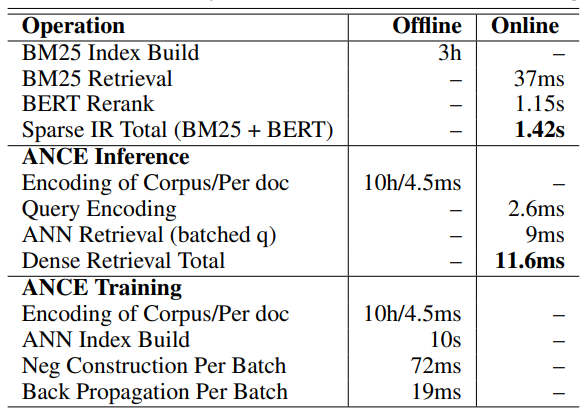
- BM25 Retrieval vs Query Encoding: 37ms vs 2.6ms, 약 14배 빠름
- BERT Rerank vs ANN Retrieval (batched q): 1.15s vs 9ms, 약 127배 빠름
- Sparse IR vs Dense Retrieval: 1.42s vs 11.6ms, 약 100배 이상 빠름
무려 100배의 속도 향상을 보임
Empirical Analyses on Training Convergence
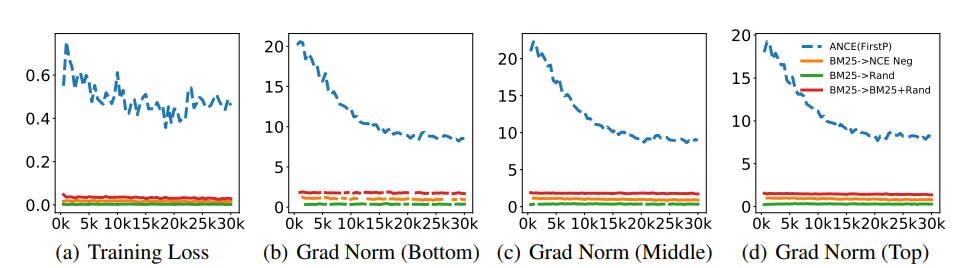
그림을 보면 BM25, Random negative 방식의 학습은 학습 loss와 기울기가 매우 작은 것을 볼 수 있지만 ANCE는 학습 과정에서 Loss와 기울기를 높게 유지함.
⇒ 모델이 정체되지 않고 이론적으로 최적화된 방향으로 빠르게 수렴하도록 유도한다는 것을 증명함.
이러한 결과는 ANCE 방식의 Dense Retrieval이 기존 Sparse IR 파이프라인 대비 무려 100배 가량 빠르면서도 더 나은 성능을 보여준다는 것을 시사함.