Proximal Policy Optimization Algorithms
Proximal Policy Optimization Algorithms (PPO)
작성자: 김두영
날짜: 2026-03-17
논문 이름: Proximal Policy Optimization Algorithms
논문 정보: arXiv 2017
To Solve
- Q-learning: 복잡한 환경에서 적용이 어려움
- Vanilla Policy Gradient: 단순하지만 데이터 효율이 낮고 불안정함
- TRPO: 안정적이나 복잡함. 일부 신경망 구조와 잘 맞지 않음 ex) dropout X
TRPO처럼 안정적이면서도 1차 최적화만으로 구현되는 RL 알고리즘 (단순성, 샘플 효율성, 성능)
Preliminary
Policy Gradient
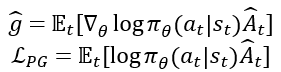
- Advantage $\hat{A}_t$의 기댓값을 최대화 하도록 학습
- 동일한 Trajectory에 대해서 여러번의 최적화를 수행하면, 정책이 과하게 변형될 수 있음. (데이터 효율성 낮음)
- Policy Gradient는 현재 정책 분포와 유사한 Trajectory에 대해서만 효율적으로 학습 가능함.
TRPO
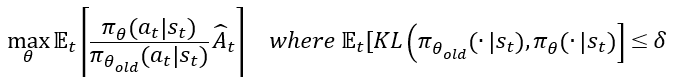
- 기존 Policy Gradient 방식에서 데이터를 샘플링할 당시의 확률로 나눔
- 정책 업데이트 크기를 KL divergence로 제한하여 기존 Policy Gradient의 문제를 해결
- KL divergence 제약조건으로 인하여, 최적화 과정에서의 연산이 복잡함.
- 또한 KL divergence 제약 조건으로 인하여 노이즈가 포함될 수 있는 모델 구조에 적용 불가능 ex) dropout
Method
Main Objective
PPO에서는 기존 TRPO의 목적함수에 Clipping과 min 연산을 적용하고 KL divergence에 대한 제약 조건을 제거하여, 안정적이면서 데이터 효율적인 강화학습 방법을 제한함.
메인 목적 함수는 다음과 같음.
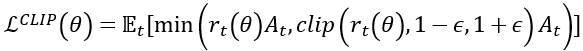
Clipping Policy Probability Rate
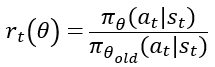
- Policy Probability Rate: 과거 정책과 현재 정책의 비율을 $r_t\left(\theta \right)$로 정의. 현 Trajectory의 Advantage 부호에 따라 $r_t\left(\theta \right)$의 증감이 결정됨
- Clipping: $r_t\left(\theta \right)$를 일정 범위 내로 제한함. $r_t\left(\theta \right)$에 따른 clip($r_t\left(\theta \right)$, 1-e, 1+e)의 값은 다음 그림과 같음.
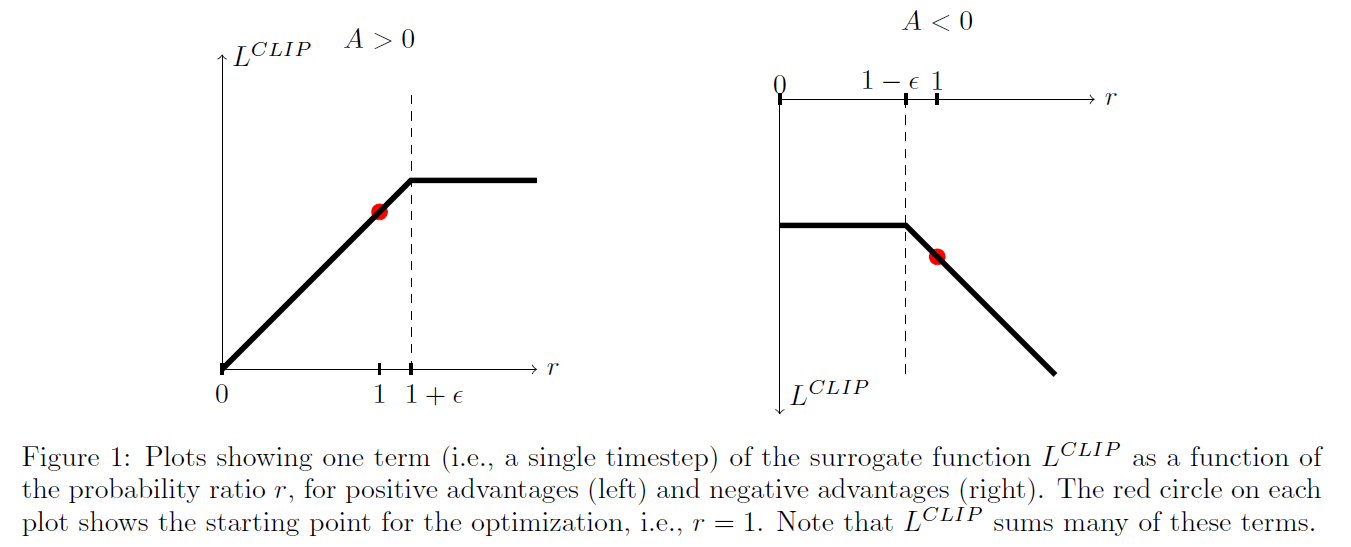
Min Operation
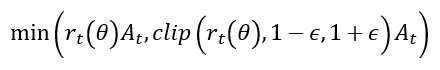
min 연산 후의 결과를 advantage $\hat{A}_t$ 의 부호에 따라 나누면:
- $\hat{A}_t > 0$: $r_t\left(\theta \right)$이 너무 큰 경우 학습 X
- $\hat{A}_t < 0$: $r_t\left(\theta \right)$이 너무 작은 경우 학습 X
즉, 이미 좋은 reward를 주는 action에 대해서 너무 큰 확률을 할당하는 경우 더 이상 학습을 수행하지 않음.
마찬가지로 나쁜 reward를 주는 action에 대해서 이미 충분히 낮은 확률을 할당하면 학습하지 않음.
Adaptive KL Penalty Coefficient (Clipping 대안)
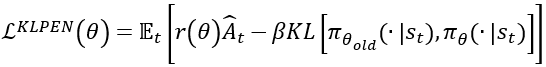
논문에서 Clipping을 대안하기 위해 KL divergence 값 기반의 패널티를 적용하는 방법을 제안함.
과거와 현재 정책의 확률 분포의 KL divergence 값 $d$에 따라서 동적으로 변하는 하이퍼파라미터 $\beta$를 정의함.
(논문에서는 Clipping이 더 좋다고 주장, 이후 연구들도 Clipping 방식 주로 이용)
Value function과 Entropy Bonus
PPO 역시 Actor-Critic 구조를 가지고 있으며, Advantage를 추정하기 위해 value network를 활용한 Generalized Advantage Estimation (GAE)를 수행함.
- value network의 손실함수
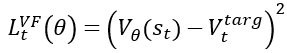
예측한 값과 목표 state value의 오차를 줄이도록 학습
- truncate GAE
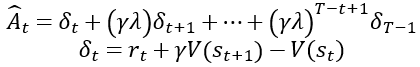
-
advantage를 예상하기 위해서 truncate GAE를 활용
advantage는 action을 통해 얻은 즉각적인 보상과 state 변화에 따른 value 차이로 계산
- entropy bonus는 학습 과정에서 다양한 trajectory를 탐색하도록 유도
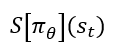
- 최종 손실 함수는 다음과 같음.
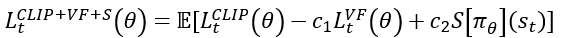
$c_i$는 각 손실 함수에 대한 가중치 상수
Experiments
Experiments Setting
- MuJoCo continuous control (T=2048, 10 epochs)
- Roboschool (T=512, 15 epochs)
- Atari에서 실험을 수행 (T=128, 3 epochs) 더 자세한 Hyperaramter는 Appendix A 참고
Main Results
주요 실험 결과
- MuJoCo continuous control
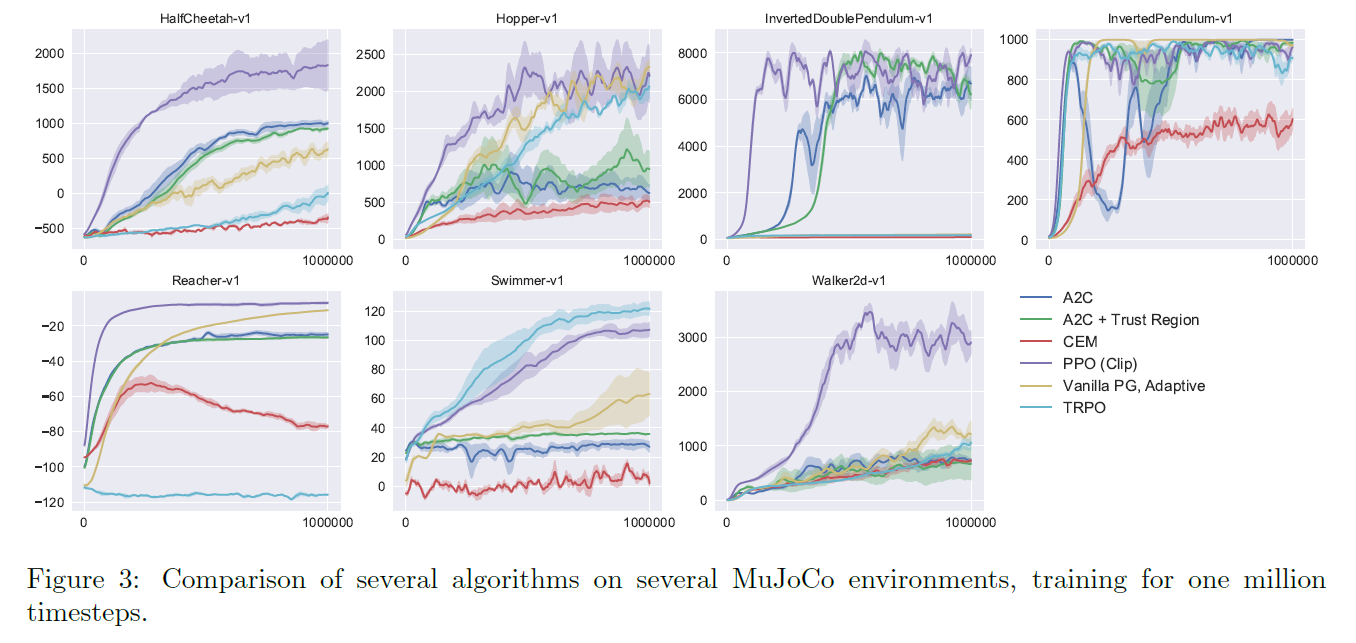
대부분의 환경에서 빠르고 높은 reward를 달성하는 것을 확인할 수 있음
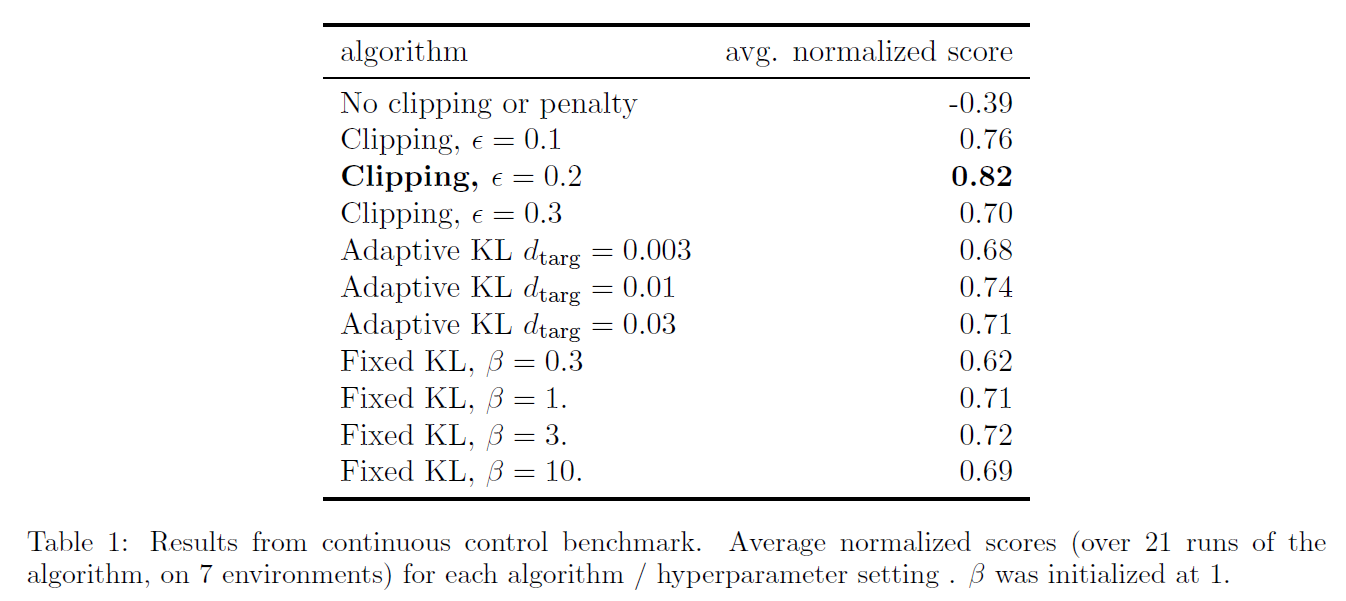
다양한 hyperarameter에 대한 실험 결과
KL penalty보다 본 논문에서 제안하는 Clipping 방법이 더 효과적인 것을 확인 가능
Clipping을 하지 않는 경우 성능이 음수로 나오는 것은, Clipping이 모델 학습 과정에서의 불안정성(붕괴)를 억제하는 것으로 볼 수 있음
- Roboschool
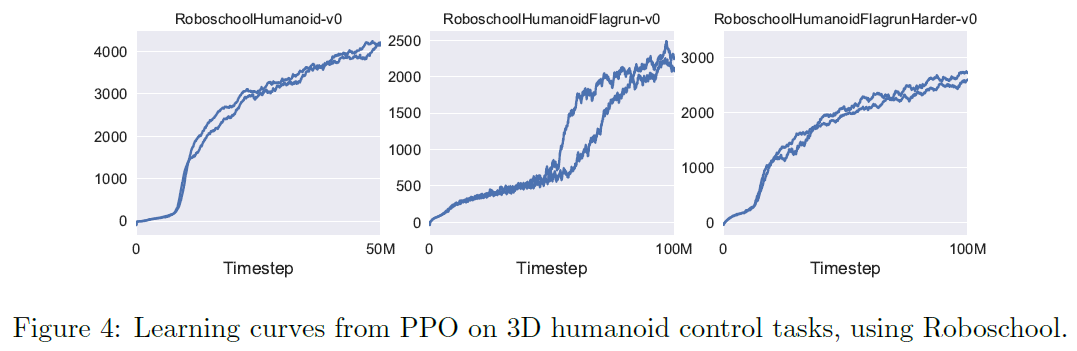
timestep에 따라서 reward가 안정적으로 증가하는 것을 확인할 수 있음
- Atari (실험 결과 일부)
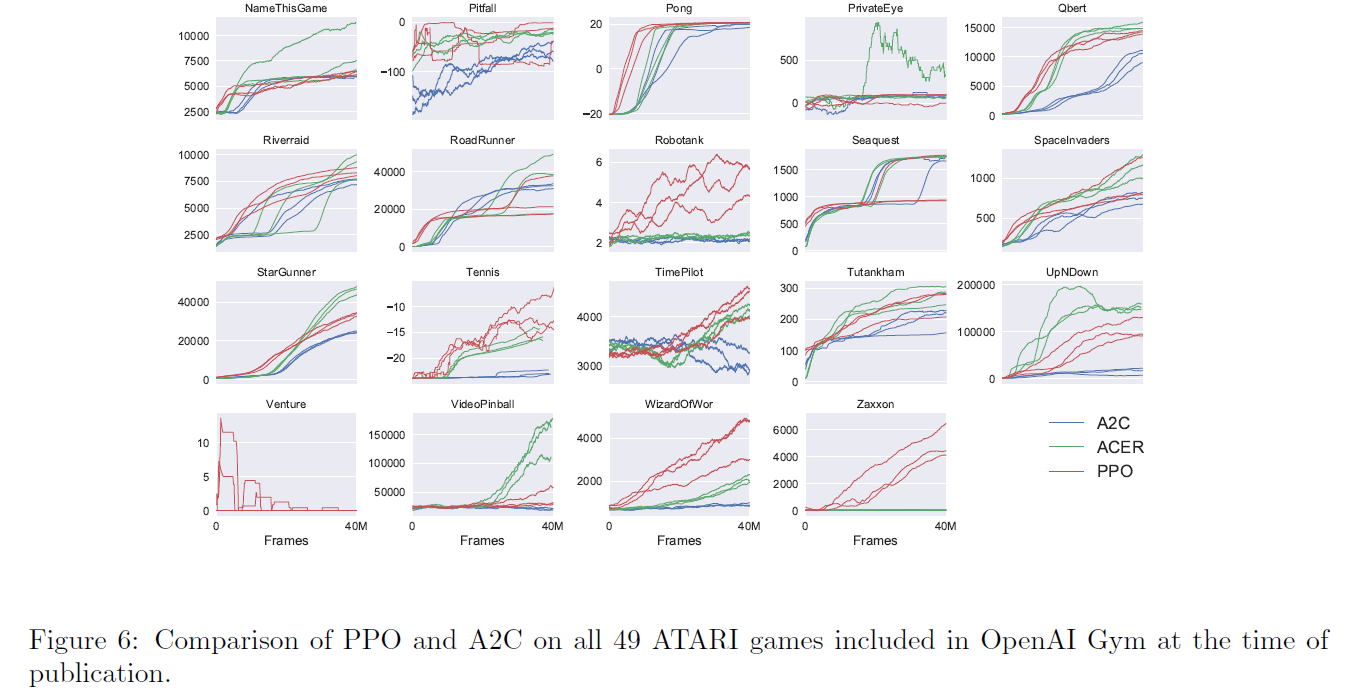
대부분의 환경에서 빠르고 높은 reward를 달성하는 것을 확인할 수 있음 (그림 크기 문제로 19개 결과만 첨부)
Conclusion
- policy update를 제한하지 않으면 policy gradient는 불안정하며, 이는 Clipping을 통해 해결할 수 있음
- 대부분의 환경에서 TRPO와 PPO가 유사한 성능을 달성함 (TRPO는 복잡한 계산 과정이 필요)
- 다양한 환경에서 PPO의 성능을 검증함