RoFormer: Enhanced Transformer with Rotary Position Embedding
RoFormer: Enhanced Transformer with Rotary Position Embedding
URL: https://arxiv.org/pdf/2104.09864
Difficulty: MEDIUM
Progress: 완료
Study Date: 2026/03/19
Summary: RoPE 포지셔널 인코딩 제안
Contribution
- Rotarty Positional Embedding(RoPE)을 제안함.
- 단어 임베딩에 직접 위치 임베딩을 더해주는 기존 방법론들과 달리 Self-Attention의 $QK^T$ 연산 직전에 위치 정보를 회전 행렬을 곱해서 위치 정보를 통합함
Introduction
트랜스포머의 attention-based 모델은 위치와 무관함. 이에 따라 학습 과정에서 위치 정보를 인코딩하기 위한 다양한 접근 방식이 제안됨.
대표적으로 사전에 정의된 함수를 사용하는 Absolute Position Embedding과 상대적인 위치 정보를 더해주는 Relative Position Embedding이 주류를 이루어왔음.
본 논문에서는 회전 행렬로 절대적 위치를 인코딩하는 한편, self-attention 수식에 명시적으로 상대적 위치 종속성을 통합하는 Rotary Position Embedding을 제안함.
Background
[Notation]
- \(\mathbb{S}_N = \{w_i \}_{i=1}^N\), $N$ input tokens with $w_i$ being the $i$-th element
- \(\mathbb{S}_N = \{w_i \}_{i=1}^N\) , $N$ input tokens with $w_i$ being the $i$-th element
-
\(\mathbf{q}_m = f_q(\mathbf{x}_m, m); \mathbf{k}_n = f_k(\mathbf{x}_n, n); \mathbf{v}_n = f_v(\mathbf{x}_n, n)\),
Attention Q, K, V features
[Absolute Position Embedding]
위치 정보를 인코딩하기 위한 가장 간단한 방법으로써 보통 정현파(sinusodial) 함수를 사용하여 인코딩함. 정현파는 보통 상대적 위치를 표현할 수 함수라고 알려짐
⇒ query는 m번째, key, value는 n번째 위치에 있다는 정보를 알려줌. 그러나 토큰 간 거리 인지 능력 부재와 max length가 넘어가는 토큰은 인코딩할 수 없는 문제 발생
\[f_{t:t\in\{q,k,v \}}(\mathbf{x}_i, i)=W_{t:t\in\{q,k,v \}}(\mathbf{x}_i + \mathbf{p}_i)\] \[\begin{cases}p_{i,2t}=\text{sin}\left(\dfrac{i}{10000^{2t/d}} \right) \\p_{i,2t+1}=\text{cos}\left(\dfrac{i}{10000^{2t/d}} \right) \end{cases}\][Relative Position Embedding]
후속 연구들에 따르면 토큰의 절대적 위치는 중요하지 않고, Query가 어떤 Key와 얼마나 떨어져 있느냐가 중요하다는 것을 밝힘. 따라서 쿼리의 위치 정보는 공통된 편향 벡터인 u,v로 대체하고, key, value도 query와의 상대적 위치 벡터로 다시 표현함.
Notation의 수식을 풀어쓰면,
\[\mathbf{q}_m^T\mathbf{k}_n=\mathbf{x}_m^T W_q^T W_k \mathbf{x}_n + \mathbf{x}_m^T W_q^T W_k \mathbf{p}_n + \mathbf{p}_m^T W_q^T W_k \mathbf{x}_n + \mathbf{p}_m^T W_q^T W_k \mathbf{p}_n\]이걸 relative의 아이디어로 바꿔쓰면,
\[\mathbf{q}_m^T\mathbf{k}_n=\mathbf{x}_m^T W_q^T W_k \mathbf{x}_n + \mathbf{x}_m^T W_q^T \tilde{W_k} \tilde{\mathbf{p}}_{m-n} + \mathbf{u}^T W_q^T W_k \mathbf{x}_n + \mathbf{v}^T W_q^T \tilde{W}_k \tilde{\mathbf{p}}_{m-n}\]- T5: \(\mathbf{q}_m^T\mathbf{k}_n = \mathbf{x}_m^T W_q^T W_k \mathbf{x}_n + b_{i,j}\)
-
DeBERTa: \(\mathbf{q}_m^T\mathbf{k}_n = \mathbf{x}_m^T W_q^T W_k\mathbf{x}_n + \mathbf{p}_m^T U_q^T U_k\mathbf{p}_n + b_{i,j}\)
⇒ projection matrix 사용
-
Transformer-XL: \(\mathbf{q}_m^T\mathbf{k}_n = \mathbf{x}_m^T W_q^T W_k \mathbf{x}_n + \mathbf{x}_m^T W_q^T W_k \tilde{\mathbf{p}}_{m-n} + \tilde{\mathbf{p}}_{m-n} W_q^T W_k \mathbf{x}_n\)
⇒ q, k 간의 상대적 위치 모델링
그러나 이러한 방법들은 지나치게 복잡함.
Methods
트랜스포머 기반 모델들은 각 토큰의 위치 정보를 Self-attention, 그 중에서도 $q_m^T k_n$ 연산에서 통합함.
본 연구에서는 내적 연산 과정에서 토큰의 위치 정보를 통합하기 위한 함수 g를 찾고자 함.
\[\left<f_q(\mathbf{x}_m, m), f_k(\mathbf{x}_n,n) \right>=g(\mathbf{x}_m, \mathbf{x}_n, m-n)\]Background: Euler’s Formula
\[e^{i \theta}=\text{cos}\theta + i \text{sin} \theta\]💡 오일러 공식이 사용된 이유?
Positional Embedding의 조건을 생각해보면,
-
$q, k$를 곱했을 때 차이($m-n$)가 나오기를 바람.
-
벡터의 크기가 폭발하면 안 됨.
오일러 공식은 수학적으로 두 가지 조건을 만족시키는 단위원 위에서의 회전이라는 기하학적 성질을 제공함.
2D Case
2D 평면과 복소 평면을 고려해보면, $x=(x_1, x_2)$ 벡터는 아래와 같음
\[f_q(\mathbf{x}_m,m)=(W_q \mathbf{x}_m)e^{im\theta}\] \[f_k(\mathbf{x}_n, n)=(W_k \mathbf{x}_n)e^{in\theta}\] \[g(\mathbf{x}_m, \mathbf{x}_n, m-n)=\text{Re}[(W_q\mathbf{x}_m) (W_k\mathbf{x}_n)^* e^{i(m-n)\theta}]\]여기서 *는 켤레복소수를 의미
⇒ 복소수 내적 결과는 실수 평면에서의 2x2 직교 회전 행렬 곱셈으로 완벽하게 치환할 수 있음.
따라서 2차원 벡터를 복소수 취급하자.
이를 풀어쓰면,
\[f_{\{q,k\}}(\mathbf{x}_m, m)=\begin{pmatrix} \text{cos }m\theta & -\text{sin }m\theta \\ \text{sin }m\theta & \text{cos }m\theta \end{pmatrix} \begin{pmatrix} W_{\{q,k\}}^{(11)} & W_{\{q,k\}}^{(12)} \\ W_{\{q,k\}}^{(21)} & W_{\{q,k\}}^{(22)} \end{pmatrix} \begin{pmatrix} x_m^{(1)} \\ x_m^{(2)} \end{pmatrix}\]General Form
\[f_{\{q,k \}}(\mathbf{x}_m, m)= R_{\theta,m}^d W_{\{q,k \}}\mathbf{x}_m\] \[R_{\theta,m}^d=\begin{pmatrix}\text{cos }m\theta_{1} & \text{-sin }m\theta_{1} & \dots & 0 & 0 \\ \text{sin }m\theta_{1} & \text{cos }m\theta_{1} & \dots & 0 & 0 \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & \dots & \text{cos }m\theta_{d/2} & -\text{sin }m\theta_{d/2} \\ 0 & 0 & \dots & \text{sin }m\theta_{d/2} & \text{cos }m\theta_{d/2} \end{pmatrix}\]여기서 \(R_{\theta, m}^d\)는 직교 행렬
이렇게 쓰게 되면 sparse matrix가 되므로 \(O(N^2)\)의 행렬 곱 대신 연산 트릭을 사용할 수 있음.
Properties
-
Long-term decay
RoPE는 학습 가능한 파라미터를 쓰지 않고, 차원마다 고정된 값으로 \(\theta_i = 10000^{-2i/d}\)을 사용함. 이것이 long-term decay를 제대로 반영할 수 있게 만듦.
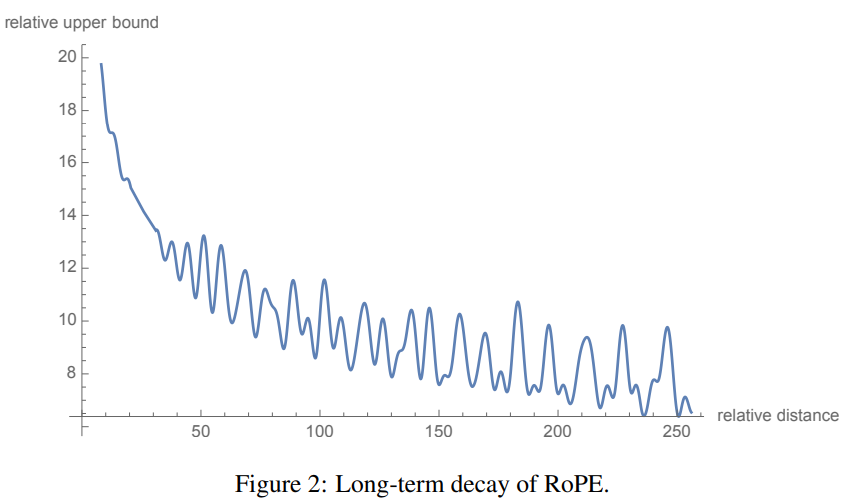
-
RoPE with Linear Attention
이전 논문들은 Self-Attention의 Q, K feature들에 직접 더해주는 방식을 사용했지만 RoPE는 단순 행렬 곱으로 가능하여 더 효율적
Computational efficient realization
약간의 수학적 트릭을 사용하면 아래의 방식으로 연산 가능해짐. 실제 구현체에서는 캐시 효율성으로 인해 이 수식과 약간 다르지만 원리는 동일함.
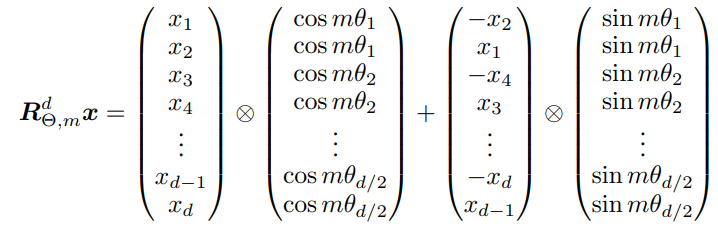
Experiments & Results
BookCorpus와 Wikipedia Corpus Foundation으로 MLM 사전학습 진행함.
BERT와 동일한 설정으로 학습하였고, max sequence length만 1024로 확장하여 추가 실험을 진행함.
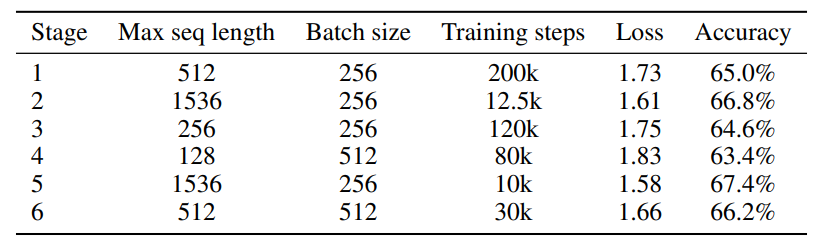
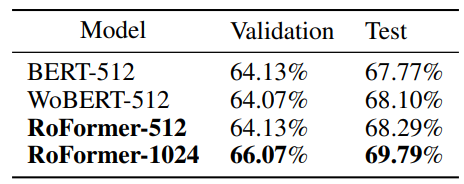
실험 결과 RoPE는 특히 Long-context에서 큰 폭의 성능 향상을 가질 수 있음을 밝힘.