DARL: Encouraging Diverse Answers for General Reasoning without Verifiers
DARL: Encouraging Diverse Answers for General Reasoning without Verifiers
: RLVR에서 Verifier 없이 Answer의 다양성 고려
1. Introduction
RLVR(Reinforcement Learning with Verifiable Rewards)는 정답의 정확성을 기반으로 보상을 제공함으로써, 수학이나 코드 생성과 같은 문제에서 뛰어난 성능을 보임.
그러나 이러한 접근은 다음과 같은 한계를 가짐.
- 정답 검증기(verifier)가 필요한 문제에만 적용 가능
- 보상이 이진적(binary)이며 정보량이 제한적
- 정답이 하나로 정의되지 않는 open-ended task에서 취약
이러한 문제를 해결하기 위해 verifier-free RL 방법론이 등장함. 대표적으로 RLPR은 reference 정답의 likelihood를 활용하여 보상을 정의함. 하지만 이 또한 reference answer에 대한 과적합이라는 한계를 보임 모델이 정답의 의미를 이해하기보다 정확히 같은 표현을 재현하는 방향으로 수렴하는 문제가 발생.
실제 많은 문제에서는 하나의 정답만 존재하지 않음.
예) 0.8km = 800m or 동일 의미의 다양한 문장 표현
하지만 기존의 RL 방법들은 정답이 유일하다는 암묵적 가정을 가짐 이로 인해 모델은 다음과 같은 문제를 겪을 수 있음.
- 다양한 표현 생성 능력 저하
- policy entropy 감소 (탐색 능력 감소)
- generalization 성능 저하
2. Preliminary
-
Reinforcement Learning with Reference Probability Reward (RLPR)
RLPR은 기존의 RLVR이 0 또는 1의 이진 reward를 주는 것과 달리, Verifier 없이도 dense한 0~1 사이의 reward를 주는 것을 목표로 한다. 이를 위해서 RLPR은 input $x$에 대해서 생성된 추론 과정 $z$와 응답 $y$에 대해서 reference 정답 $y^*$의 생성 확률을 통해 계산된 리워드 $\hat r$을 부여한다. 이때 $\hat r$은 추론 과정에 대한 영향만 고려하기 위하여 다음과 같이 계산된다. 이때 $f(y^*\mid x)$는 input x에 대해서 output $y^*$가 나올 확률의 per-token probability의 aggregation 함수이다.
\[\hat r= \mathsf{clip}(0, f(y^*|x, z)-f(y^*|x))\]이러한 리워드는 모델이 예측한 정답이 $y^*$과 정확하게 일치하지 않더라도, $y^*$의 확률에 논리적으로 도움이 되는 추론 과정에 대해서 positive한 학습 signal을 제공할 수 있다. 최종적으로 RLPR의 objective function은 다음과 같다.
\[\nabla \mathcal{J}_{RLPR}(\theta)=\mathbb{E}_{o \sim \pi_{\theta}(\bullet|x)}[\hat r \nabla \log \pi_{\theta}(o|x)]\]
3. Method
Verifier 없이 Reference answer y*와 일관성을 유지하면서도 다양한 답변에 대한 보상을 제공하기 위해 다음과 같은 advantage를 설계함.
3.1 Diversity Reward
DARL은 다음과 같은 생성된 답변과 reference의 차이를 정의함.
- 입력: $x$
- 추론 과정: $z$
- 생성된 답변: $y$
- reference 정답: $y^*$
- 모델 내부 확률 기반 함수: $r(\bullet)$ 논문에서는 token들의 평균 확률을 사용했다고 함.
여기서, $\Delta r$ 이 작으면 생성된 답변이 reference와 유사하고, 크면 오답일 가능성이 높음.
3.2 Final Reward Function
\[\bar{r}=\alpha\, r\!\left(y^{*}, z, x\right)+\beta\,\Delta r\;\mathbf{1}\!\left[\Delta r\le \tau\right]\]여기서:
- $\alpha$: reference 정답에 대한 가중치 (exploitation)
- $\beta$: reference와 유사한 답에 대한 가중치 (exploration)
- $\tau$: 임계값
Diversity Reward가 임계값 이하인 경우에는 추가 보상을 제공함. 임계값 이상인 경우에는 아예 의미가 다른 값을 생성했다고 추정하여 보상 제공 X. 유사한 확률 값을 가진다는 것은 대체적으로 reference와 모델이 예측한 답이 의미적으로 유사하다고 볼 수 있음.
3.3 Dynamic Thresholding
Threshold $\tau$는 동적으로 조정되는 값
\[\Delta r \le \frac{r\!\left(y^{*}, z, x\right)}{\gamma}\]- 모델이 reference를 잘 맞출수록 → 더 넓은 다양성 허용
- 모델이 refernece를 잘 못맞추는 경우 (아직 불안정할 경우) → 다양성 제한
이는 학습 초기에 안정적인 답을 학습하는데 집중하고, 후반의 학습에서 다양한 탐색을 권장하는 효과를 갖음. 결국 모델의 확률 값을 기반으로 의미적 유사성을 판단하는 구조이기 때문에, reference를 더 잘 맞춰야 Diversity Reward의 정확도가 올라간다고도 볼 수 있음.
4. Experiments
4.1 Experiment Setting
4.1.1 Dataset
- Train: WebInstructed corpus
4.1.2 Models
- Llama3.1-8B-Instruct
- Qwen2.5-7B-Base
4.2 Reasoning Task
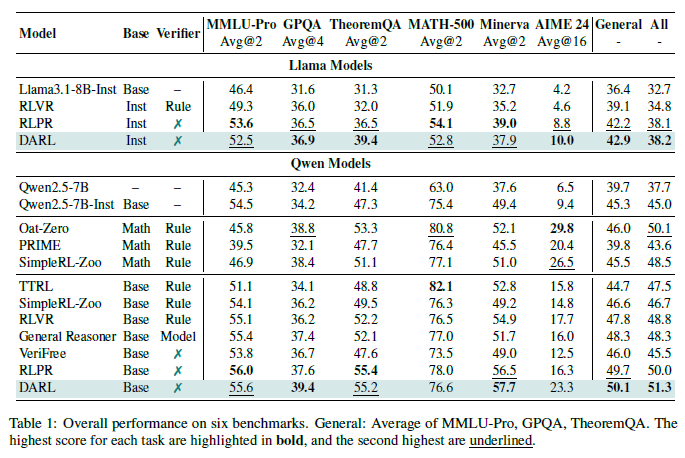
- GPQA, AIME 등에서 유의미한 성능 향상
4.3 General Domain Task
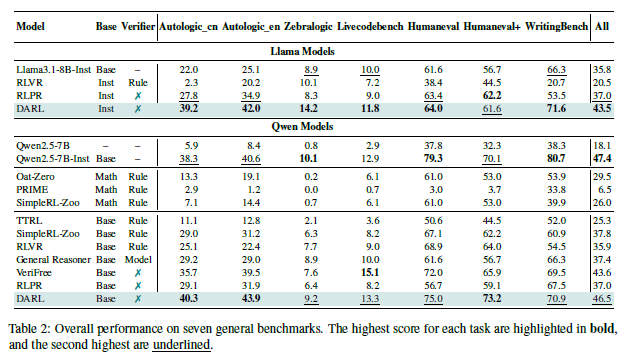
- 다양한 Task에서도 성능 향상
4.4 Analysis
4.4.1 Diversity
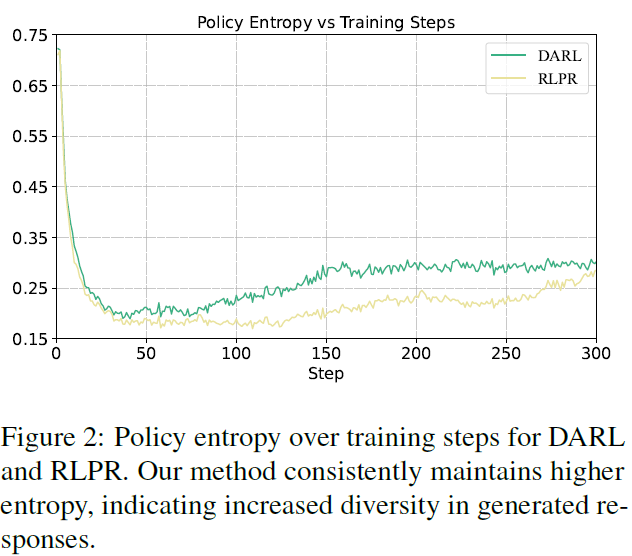
학습 과정에서의 Entropy가 DARL은 증가하는 경향을 가짐. (정답을 잘 맞추기 시작하면 다양한 탐색에 집중)
4.4.2 Ablation
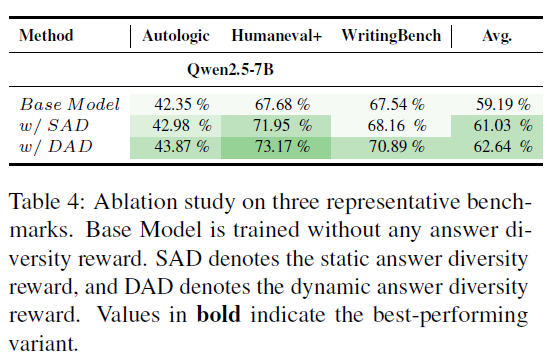
- SAD: Static threshold를 사용한 경우
- DAD: Dynamic threshold를 사용한 경우 (see 3.3)
이를 보아 reference 정답을 생성할 확률에 기반하여 Dynamic하게 threshold를 조절하는 것이 더 효과적임을 확인할 수 있음
5. Conclusion
- DARL은 다양한 정답에 더 많은 보상을 주기 위한 reward를 제안함. 이로 인하여 학습된 모델은 특정 reference만 생성하는 것이 아닌 다양한 답을 생성할 수 있음.
- 이러한 답의 다양성을 보장하는 것은 다양한 도메인에서의 적용을 가능하게 함. (글쓰기 등 명확한 답이 없는 Task에서의 강화학습이 가능해짐)