HiPRAG - Hierarchical Process Rewards for Efficient Agentic Retrieval Augmented Generation
HiPRAG - Hierarchical Process Rewards for Efficient Agentic Retrieval Augmented Generation
Conference: EMNLP findings 2025 Date: March 25, 2026 4:22 PM
📋 Paper Info
URL: HiPRAG: Hierarchical Process Rewards for Efficient Agentic Retrieval Augmented Generation (ICLR’26)
GitHub: https://github.com/qualidea1217/HiPRAG
📕 Introduction
RAG는 쿼리를 탐색하고, 외부 지식을 통합하고, mutli-step 추론하는 모든 과정을 자동으로 할 수 있는 Agentic RAG로 발전하고 있다. 특히, 최근에는 LLM이 tep-by-step 추론 과정에서 검색할 문서 내용과 검색 타이밍을 결정할 수 있는 능력(when and what to retrieve)을 기르기 위해 강화 학습을 활용하는 방향으로 가고 있다.
그러나, Agentic RAG는 over-search와 under-search 문제가 있다. over-search는 블필요하거나 중복된 외부 지식을 사용하는 상황을 말하고, under-search는 외부 지식이 필요한 상황임에도 불구하고 검색에 실패한 상황을 말한다. 즉 단순히 검색 엔진과 LLM을 묶는 방법으로는 충분하지 않을 뿐더러 Agent가 검색 엔진을 다룰 수 있도록 최적화하는 과정이 필요하다.
HiPRAG (Hierarchical Process reward framework for sgentic RAG)는 rule-based 방식으로 reasoning trajectory를 구조화된 step들로 구성한다. 또한 trajectory의 최적 step 길이가 길어진 만큼 선형적으로 보너스 보상을 지급하는 보상 체계를 구축하고, 학습 도중에 step 중간마다 over-search와 under-search를 감지할 수 있는 LLM을 두어 보너스 보상의 정도를 조절한다.
🔎 Related Work
Search-R1 (COLM’25)
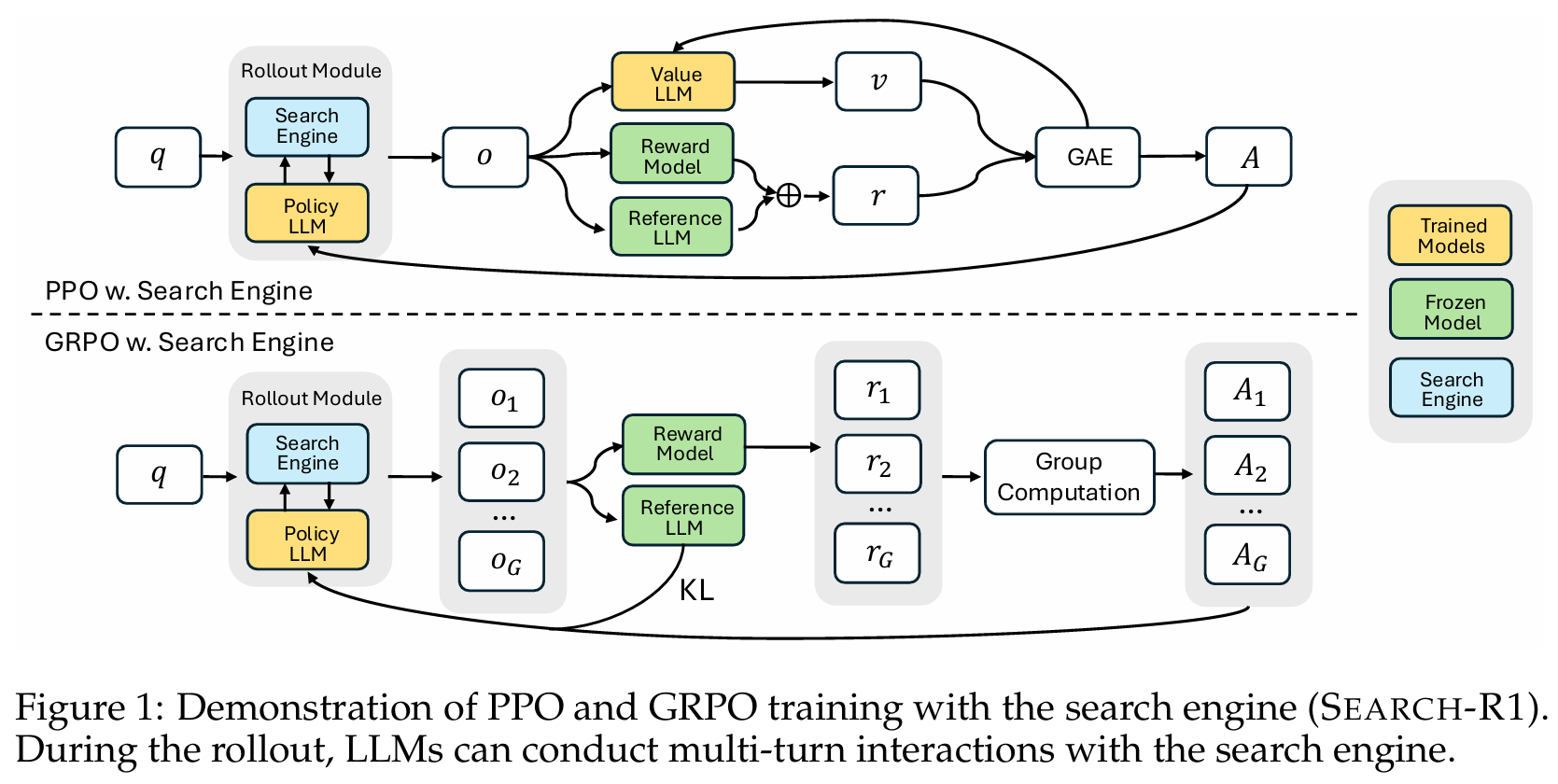
Search-R1의 핵심 아이디어는 검색 엔진을 environment에 고정해두고, 검색이 필요한 상황에서 API처럼 호출할 수 있게 강화 학습을 진행하여 End-to-end RAG 파이프라인을 구축하는 데에 있다.
End-to-end RAG 구현에 있어 주요 과제 중 하나가 어떤 형태로든 학습을 진행할 때 어떻게 검색기를 뚫고 input에 역전파를 할 수 있는지이다. 여기서 Search-R1은 단순히 검색 토큰에 대해 loss masking을 하고 텍스트를 정해진 형식에 맞춰 생성하도록 했다. 해당 예시는 아래의 그림을 참고하도록 하자.

Search-R1은 강화학습을 이용해 step-by-step reasoning을 진행하는 프레임워크를 제안했다. 먼저, 최초의 question이 들어오면
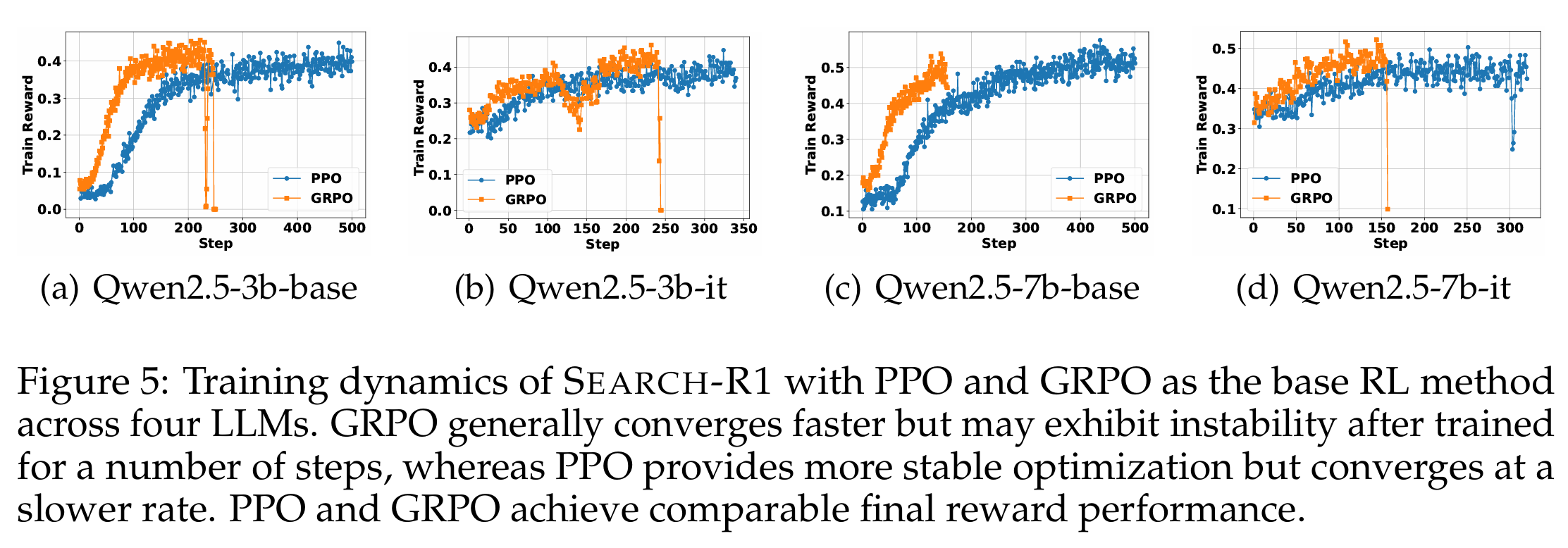
TMI) Search-R1의 학습은 PPO, GRPO 둘 중 하나를 사용하여 학습할 수 있다. 그러나 GRPO를 사용할 경우, 특정 step 이후로 넘어가면 학습이 붕괴되어 더 안정적인 PPO를 메인으로 사용했는데, 해당 현상은 본 논문에서도 동일하게 나타났다.
⚙️ Methodology
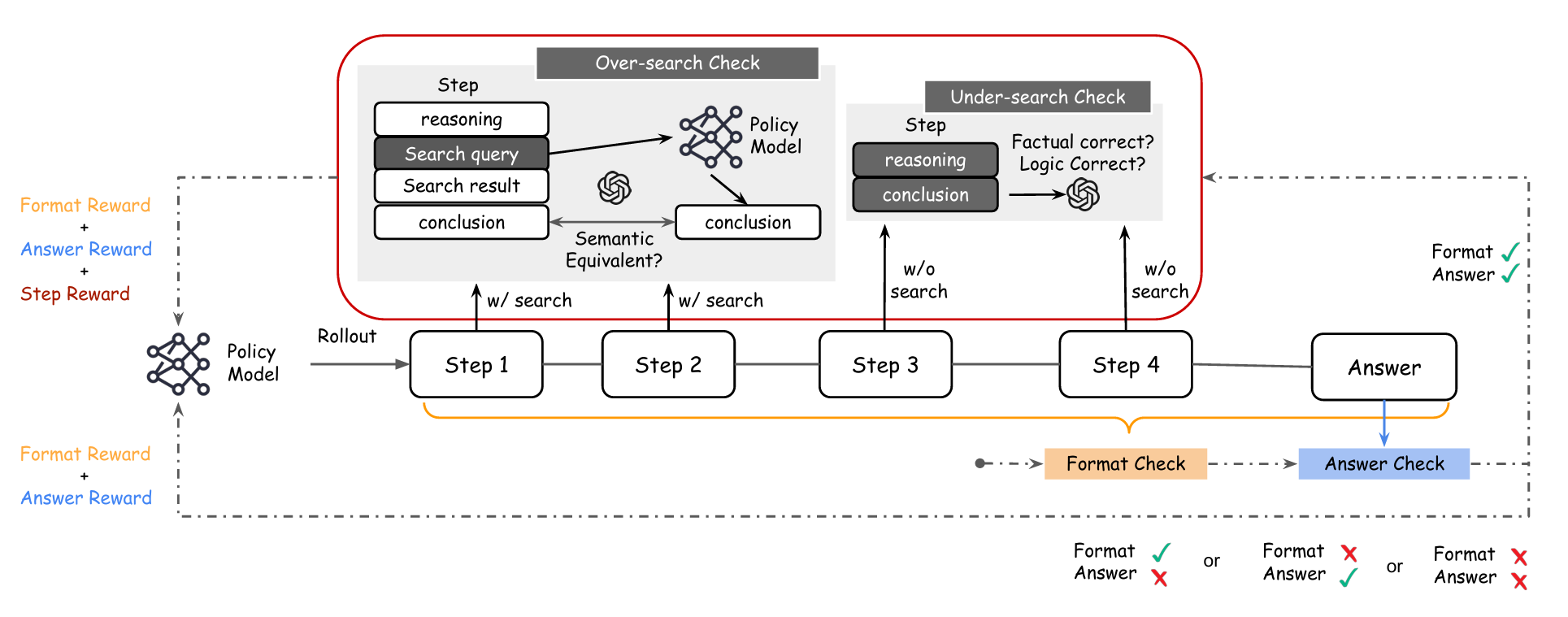
사진은 HiPRAG의 동작 흐름을 간략히 나타내는 그림이다. step1, 2는 검색이 필요하다 판단되어 over-search를 확인하는 과정을 나타내고, step3, 4는 검색이 필요없다고 판단되어 under-search를 확인하는 과정을 나타낸다. 단순히 예제를 나타내는 것이기에, 실제로는 각 step마다 검색이 필요한지 불필요한지는 제각각 결정된다.
1. Reasoning Trajectory를 parsable steps으로 분해하는 과정
Search-R1과 HiPRAG의 가장 큰 차이점은, reasoning step을 명시적으로 구분했다는 점이다. 아래 사진은 Search-R1와 HiPRAG의 reasoning trajectory 형식을 비교하여 나타낸 것이다.

저자들은 이러한 Search-R1의 형식을 다음과 같은 이유로 비판하고 있다.
- 모호한 Step간의 경계: Search-R1의 경우 검색 쿼리와 문서 사이에
블록을 끼워넣는 형태로 추론 과정을 전개해왔는데, 저자들은 이러한 구조가 step 간의 경계를 모호하게 만든다고 지적한다. 블록 내의 내용을 보면 이전 step의 결론과 현재 행동에 대한 계획이나 추론들을 같이 섞어버리기에, 독립된 step의 역할을 수행하지 못한다. - 암묵적 내부 추론: 검색을 요구하지 않는 step에서는 온전히 모델의 내부 지식에 의존해야 하는데, 이런 경우는 명시적으로 따로 태그되지 않는다. 즉 현재 step이 검색 쿼리 짜기 위한 내용인지, 아니면 이미 모델의 내부 추론으로 완성된 내용인지 구분하기 어려워지고, 이는 RL의 보상 체계를 구축하는데 어려움을 겪는다.
따라서, 저자들은 기계가 pasrsing 가능한 형식으로 trajectory $T$를 다음과 같이 분해하고자 한다.
\[T=\{s_1,s_2,\dots,s_n,a\},\quad s:\text{step}, \quad a:\text{final answer}\]위의 step은 search step $s^R$과 non-search step $s^{NR}$ 두 가지로 나눌 수 있다. 각각 검색이 필요한 step, 검색이 필요하지 않은 step이며, 모든 step은 단 하나의
추론 내용인 $r_i$과 현재 step의 결론인 $o_i$은 공통으로 들어간다. $q_i$는 검색 엔진에 사용하고자 할 쿼리이며, $c_i$는 검색된 문서이다.
2. Suboptimal Search(Over-Search, Under-Search)에 대한 실시간 감지
1) Over-Search 감지
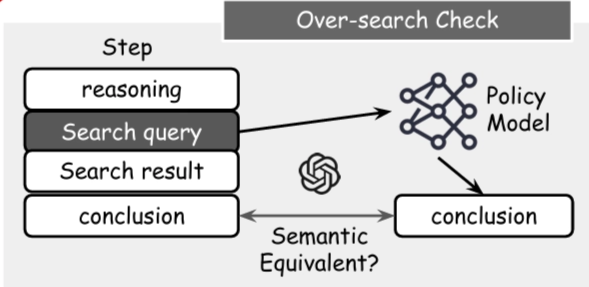

Over-Search는 이미 중복되거나 불필요한 정보를 검색하는 경우를 말한다. 실제로 검색 쿼리로 문서를 가져온 후 내린 결론과, 쿼리만 입력하여 내부 지식을 이용해 내린 결론을 비교하여 둘 다 일치하면 중복된 정보를 가져왔다고 판단하여 Over-Search로 간주한다.
2) Under-Search 감지
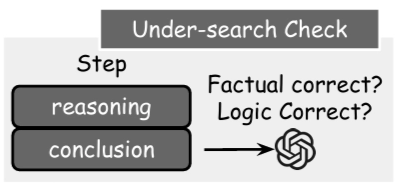

Under-Search는 검색이 필요한 상황에도 불구하고 검색이 필요하지 않다고 판단하는 경우인데, 이러한 경우에는 조금 복잡하다. 간혹 현재 step만을 두고 봤을 때 불완전하거나 suboptimal하게 보일 순 있어도, 국소적으로는 맞는 중간 step인 경우, 그러니까 빌드업을 위한 과정인 경우가 있기 때문이다.
따라서, 이러한 step에 패널티를 부여하지 않도록 하기 위해, 저자들은 추론 내용과 결론이 올바르고 인과적인 논리가 성립되는 경우에 대해서는 Under-Search로 보지 않았다. 해당 내용은 위 프롬프트에서 확인할 수 있다.
3. 계층적 보상 체계
정답의 여부를 확인하고 정해진 형식에 맞춰 구조화된 텍스트를 생성하는 것도 중요하지만, suboptimal search0가 발생하지 않도록 보너스 보상을 설계하는 것도 중요하다.
\[R(T)=A(T)(1-\lambda_f)+\lambda_fF(T)+\lambda_pA(T)F(T)\frac{N_\text{corr}(T)}{N(T)}\]$A(T)\in{0,1}$ 는 final answer에 대한 보상, $F(T)\in{0,1}$ 는 format에 대한 보상이다. 두 보상은 hyperparameter $\lambda_f$에 의해 가중합으로 조절된다.
$N(T)$은 해당 trajectory의 전체 step의 개수를 나타내고, $N_\text{corr}(T)$는 해당 trajectory에서 suboptimal step이 아닌 step의 개수를 나타낸다. 따라서, $N_\text{corr}(T)$는 아래와 같이 표현할 수 있다.
\[N_\text{corr}(T)=|\{s^R\in(T):\lnot\text{Over}(s^R)\}|+|\{s^{NR}\in(T):\lnot\text{Under}(s^{NR})\}|\]final answer와 format 모두 맞았다고 가정하면($A(T)=F(T)=1$), 보상은 $R(T)=1+\lambda_p\frac{N_\text{corr}(T)}{N(T)}$으로 단순화되어 표현할 수 있다. hyperparameter $\lambda_p$를 잘 조절하여 균형을 이루는 것이 중요해 보인다.
📊 Experiments
참고 사항
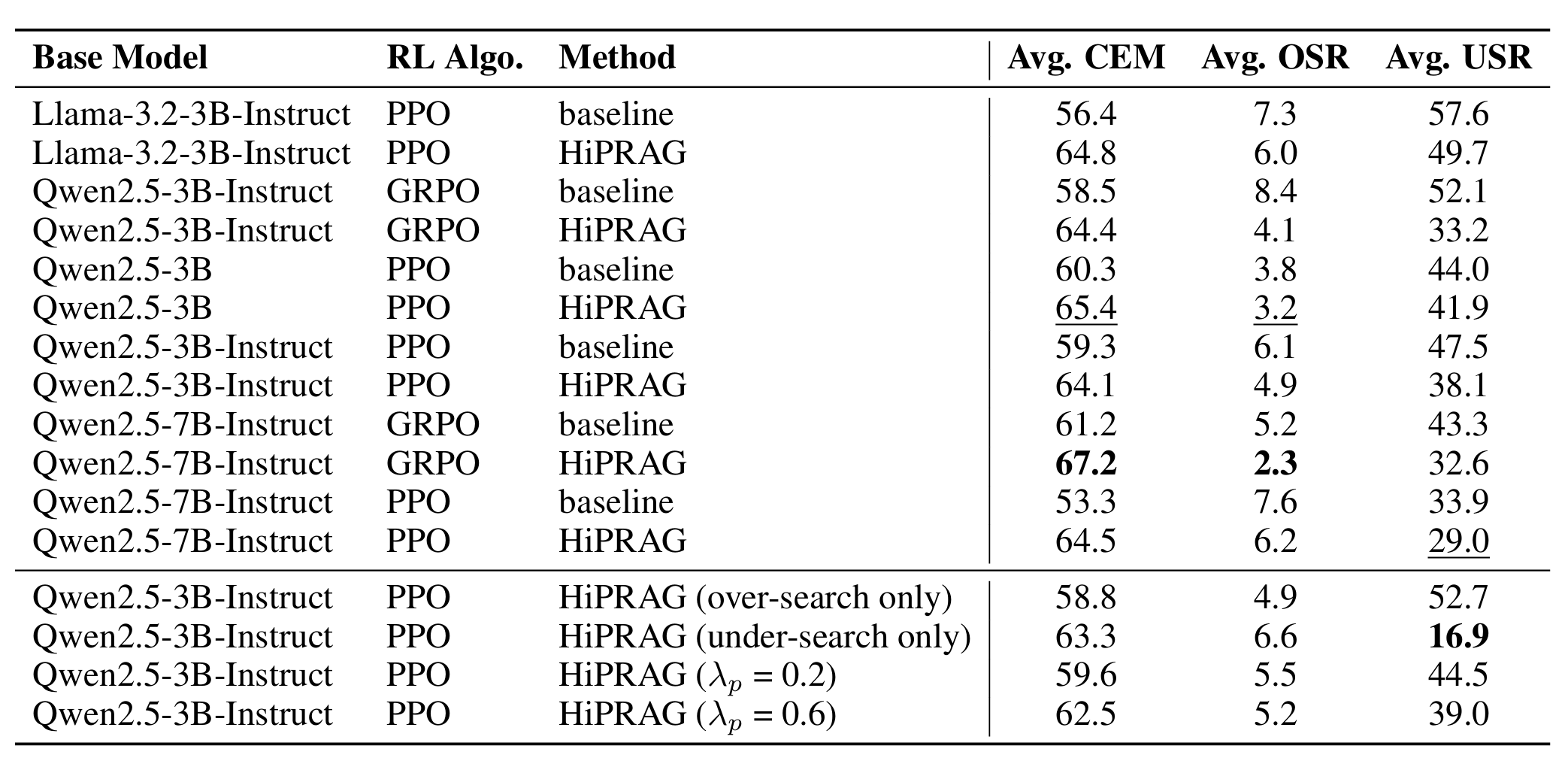
- 논문에서는 정확도 평가를 위해 CEM(Cover Exact Match)를 사용했고, OSR과 USR이라는 새로운 지표를 사용했다. OSR과 USR은 각각 Over-Search Rate, Under-Search Rate이다.
- 사용한 모델은 Qwen2.5-(3B/7B)-Instruct을 사용했고, Over-Search와 Under-Search 감지를 위해 사용한 모델은 각각 GPT-4.1 mini/GPT-5 mini이다.
- Search-R1과 마찬가지로 PPO를 주로 사용
- hyperparameter는 $\lambda_f=0.2,\lambda_p=0.4$ 로 세팅했다.
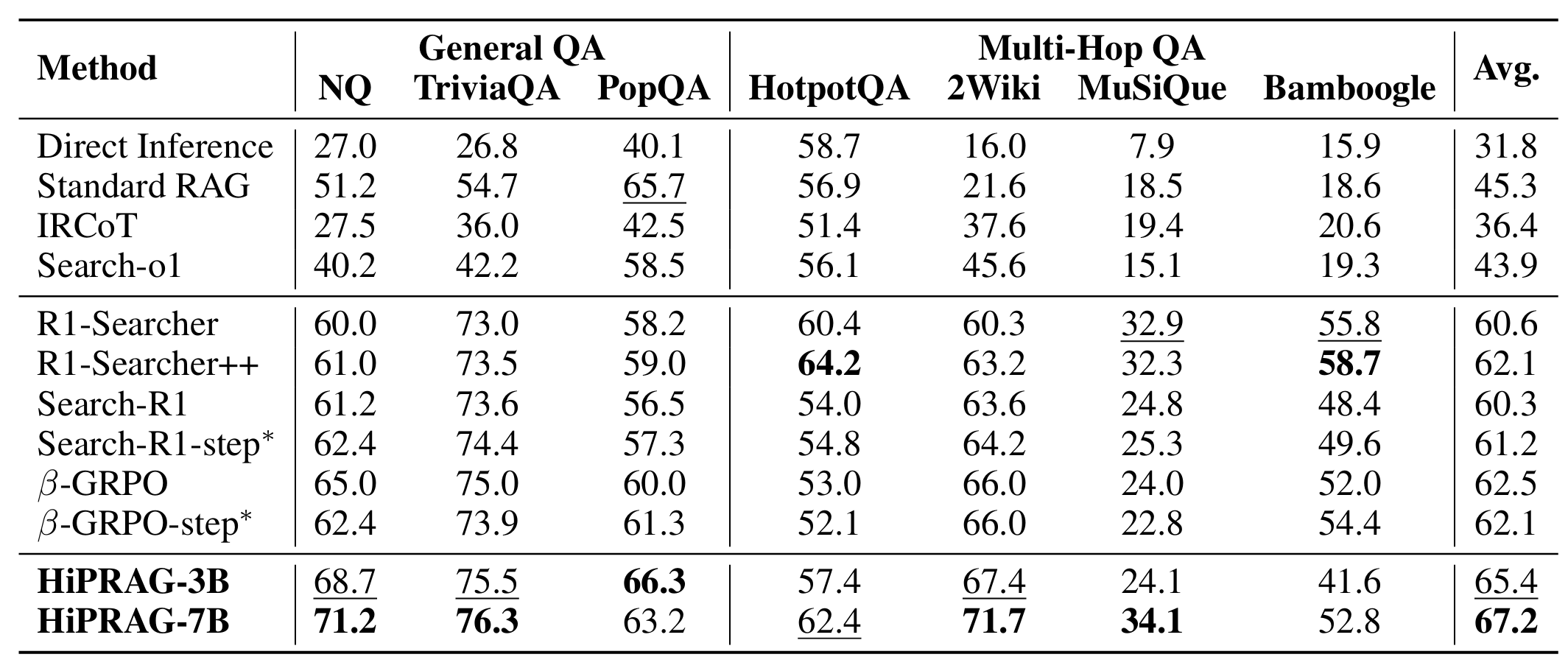
- step*은 보상 기존 베이스라인의 보상 체계를 사용하되, 출력 format만 HiPRAG의 형식대로 나타낸 것
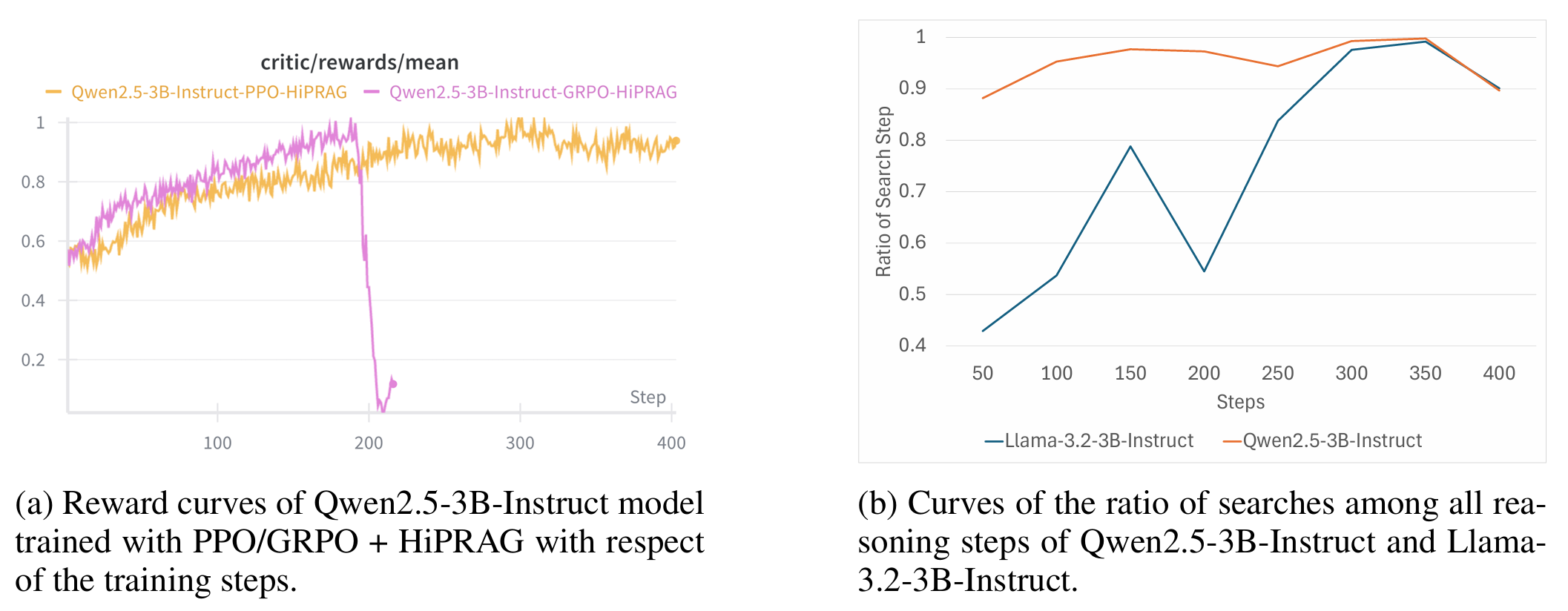
- Search-R1 때와 똑같은 GRPO 학습 붕괴 현상 발생
- Llama 모델의 경우 학습 초기에 내부 지식에 의존하는 경향이 있음