Research
Fields
1. 대화 시스템
대화 시스템(Dialogue System)은 인간과 컴퓨터 간의 상호작용을 가능하게 하는 기술이다.

일반적 대화는 문서와는 달리 구어체 표현을 사용하고, 생략 및 대용어 표현이 빈번히 나타나며, 표정이나 손짓 등 언어 이외의 다양한 수단을 통해 의사를 전달한다. 지능형 대화 시스템 개발은 유비쿼터스 환경에서 가장 유용한 HCI (Human Computer Interaction) 기술이며, 지능형 로봇 개발 등에 사용되는 핵심 기술이다. 최근 대화 시스템이 발전하고 다양한 형태의 대화 데이터가 많아지면서 대화 시스템에 기대하는 사용자의 요구 또한 다양해졌다. 현재는 다음과 같은 다양한 대화 시스템의 소분야에 대한 연구를 진행하고 있다.
- 특정 도메인에 한정되지 않고 일반적인 상식을 가지고 다양한 도메인에 대해 사람과 대화하는 오픈 도메인 대화(Open-Domain Dialogue) 모델
- 사용자의 특정 요구사항을 해결하고, 이와 관련된 답변을 제공하는 작업 지향 대화(Task-Oriented Dialogue) 모델
- 사용자의 페르소나를 추출 및 분석하고, 이에 맞는 대화를 제공하는 페르소나 대화(Persona-based Dialogue) 모델
- 다자 간의 대화 상황(토론, 토의 등)에서 대화를 분석하고, 해당 상황에서의 최선의 답변을 생성하는 다자간 대화(Multi-Party Dialogue) 모델
- 외부 지식 기반 대화 시스템
- 대화 내 상식 추론을 이용한 동적 페르소나 기반 대화 시스템
- 유사 발의를 활용한 초점 기반 다자대화 대화시스템
- 지식 기반 응답 생성 모델을 이용한 대화 시스템
- 통사적 담화 그래프를 이용한 대화 상태 추적 모델
- 가상환경 쇼핑 보조를 위한 대화형 인공지능 에이전트
2. 오픈 도메인 질의응답 시스템
Open-Domain QA(Open-Domain Question Answering)는 사용자가 제시한 질문에 대해 대규모의 비구조화된 데이터나 문서로부터 적절한 답변을 찾아 제공하는 시스템이다.

주로 인터넷이나 대규모 텍스트 데이터베이스에서 정보를 검색해 사용자가 원하는 답을 제공하는 방식으로 동작한다. 이러한 시스템은 검색 엔진, AI 기반 비서 등 여러 응용 분야에서 활용된다.
아래 그림은 질의응답의 일반적인 구성을 보여주는 예시이다.
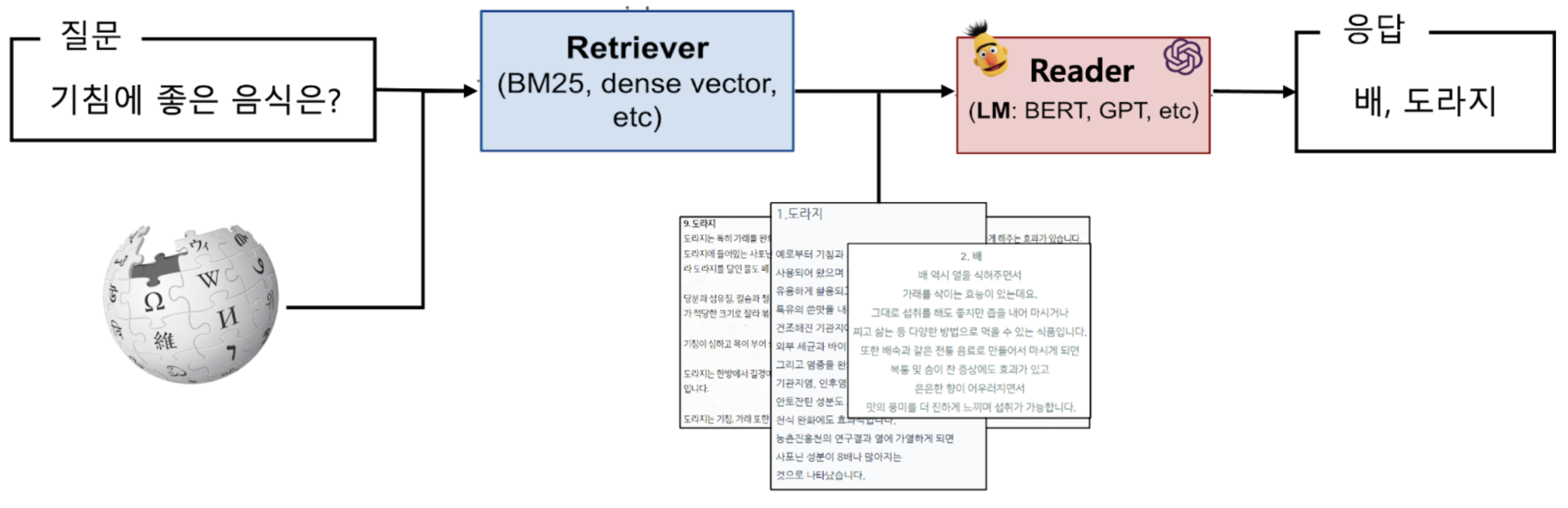
Open-Domain QA의 주요 구성 요소 및 핵심 기술은 다음과 같다.
- 문서 검색(Document Retrieval): 사용자의 질문과 관련된 문서를 대규모의 데이터베이스에서 찾아내는 단계이다. 이 단계에서는 전통적인 검색 엔진 기술이나 BM25, TF-IDF와 같은 정보 검색 기법이 사용된다.
- 질의 이해(Query Understanding): 사용자가 입력한 질문의 의미를 이해하고, 질문에서 중요한 개체나 키워드를 추출하는 과정이다. 자연어 처리(NLP) 기술을 이용해 질문의 의도를 파악하고 필요한 정보를 찾아내기 위한 준비를 한다.
- 다정답 추출 및 생성(Answer Extraction and Generation): 질문과 관련된 문서나 데이터에서 정답을 추출하거나 생성하는 과정이다. 기계 독해(Machine Reading Comprehension, MRC) 기술을 사용해 문서 내에서 질문에 가장 적합한 텍스트를 찾아 정답을 추출하거나, 검색된 문서의 정보를 입력받아 생성 모델을 통해 정답을 생성한다. 대표적인 모델로는 BERT, RoBERTa, T5 등이 있다.
- 설명 가능한 질의 응답 시스템
3. 정보 검색
정보검색 시스템(Information Retrieval System)은 대량의 데이터나 문서에서 사용자가 필요한 정보를 효과적으로 찾아주는 시스템이다.

인터넷 검색 엔진, 디지털 도서관, 기업 데이터베이스 등 다양한 분야에서 활용되며, 사용자의 질의에 따라 관련된 문서나 데이터를 검색해 제공한다. 오픈 도메인 질의응답 시스템에서 문서를 검색하는 과정과 일치하지만 답변 생성이 목적이 아닌 정확한 문서를 가져오는 것이 목적인 부분에서 차이가 존재한다.
정보검색 시스템의 주요 구성 요소 및 핵심 기술
- 문서 컬렉션(Document Collection): 검색 대상이 되는 모든 문서나 데이터의 집합이다. 문단 혹은 3~5개의 문장단위로 구성하여 사용하기도 한다.
- 색인(Indexing): 문서에서 중요한 키워드나 특징을 추출해 색인을 생성하는 과정이다. 이를 통해 문서 검색이 빠르고 정확하게 이루어질 수 있다. 대표적인 방법으로 TF-IDF(Term Frequency-Inverse Document Frequency), DPR(Dense passage retrieval) 등이 사용된다.
- 질의 처리(Query Processing): 사용자가 입력한 질의를 이해하고, 시스템이 처리할 수 있는 형태로 변환한다. 자연어 질의의 경우, 형태소 분석과 같은 기술을 통해 핵심 키워드를 추출하고 검색 가능한 형태로 만든다.
- 검색 및 매칭(Search and Matching): 색인된 문서와 사용자의 질의를 비교해 관련성 있는 문서를 찾아내는 과정이다. 문서와 질의 간의 유사도를 계산하여 가장 적합한 결과를 제공한다.
- 랭킹(Ranking): 검색된 문서를 관련성이나 중요도에 따라 정렬하는 과정이다. 랭킹 알고리즘을 사용해 사용자가 찾고자 하는 정보의 우선순위를 결정하게 된다.
- TBD
- 저자원 환경에서 도메인 과적합 문제를 방지하기 위한 문서분류 기법
- 사전학습을 이용한 정보검색 시스템
4. 생성형 인공지능
Controllable Text Generation(조절 가능한 텍스트 생성)은 사용자가 원하는 특정 조건에 맞춰 텍스트를 생성하는 기술이다. 예를 들어, 생성되는 텍스트의 길이, 감정(긍정적, 부정적), 주제, 문체(격식적, 비격식적) 등을 제어할 수 있다.
주요 개념
- 속성 제어: 텍스트의 특정 속성(예: 주제, 감정, 스타일 등)을 사용자가 설정한 대로 제어한다. 최근에는 단일 속성뿐만 아니라 다양한 속성을 제어하는 연구들이 활발하게 이루어지고 있다.
- 조건부 생성: 주어진 조건에 따라 텍스트를 생성한다. 예를 들어, 대화 시스템에서는 사용자 질문에 따라 적절한 답변을 생성할 수 있다.
이 기술을 통해 사용자 맞춤형 텍스트 생성을 더 효율적으로 할 수 있어, 다양한 AI 응용 분야에서 활용되고 있다.
- TBD
- TBD
5. 텍스트 마이닝
텍스트 마이닝(Text Mining)은 대량의 텍스트 데이터에서 유용한 정보를 추출하고 패턴을 발견하는 과정이다. 주로 다음과 같은 주요 작업들이 포함된다
- 텍스트 분류: 텍스트를 사전에 정의된 카테고리 중 하나로 분류한다.
- 텍스트 요약: 긴 텍스트에서 핵심 내용을 생략하지 않으면서 짧고 간결하게 요약하여 제공한다.
- 감성 분석: 텍스트에서 감정이나 의견을 추출하여 긍정적, 부정적 또는 중립적인 감정을 분석한다.
이러한 작업들은 자연어 처리 기술을 활용하여 이루어지며, 텍스트 데이터를 더 잘 이해하고 유용한 정보를 얻을 수 있다.
- 질의 집중 의미 그래프를 활용한 질의 기반 문서 요약
6. 자연어 처리 기반 기술
자연어 이해 그룹에서는 자연어 문장의 구조를 인식하고 이를 의미구조로 변환해 주는 자연어 이해 시스템을 개발하는 것을 목표로 하고 있다. 현재 다음과 같은 언어 처리 모델들이 자연어처리에 필요한 기반 기술들이다.
- 형태소 분석 (POS(Part-Of-Speech) Analysis)모델
- 개체명 인식 (Named-Entity Recognition) 모델
- 구문 분석 (Syntactic Analysis) 모델
- 의미 분석 (Semantic Analysis) 모델
- 담화 분석 (Discourse Analysis) 모델
- 대용어처리 (Anaphora Analysis) 모델
- 단어 의미 중의성 (Word Sense Disambiguation) 해소 모델
이들 자연어의 처리의 기반 기술은 정보검색이나 데이터 마이닝 등 여러 응용시스템에서 매우 유용하게 사용될 수 있다.
아래의 예시는 본 연구실이 소장하고 있는 언어분석기(DANCHU)의 전체 구성도이다.
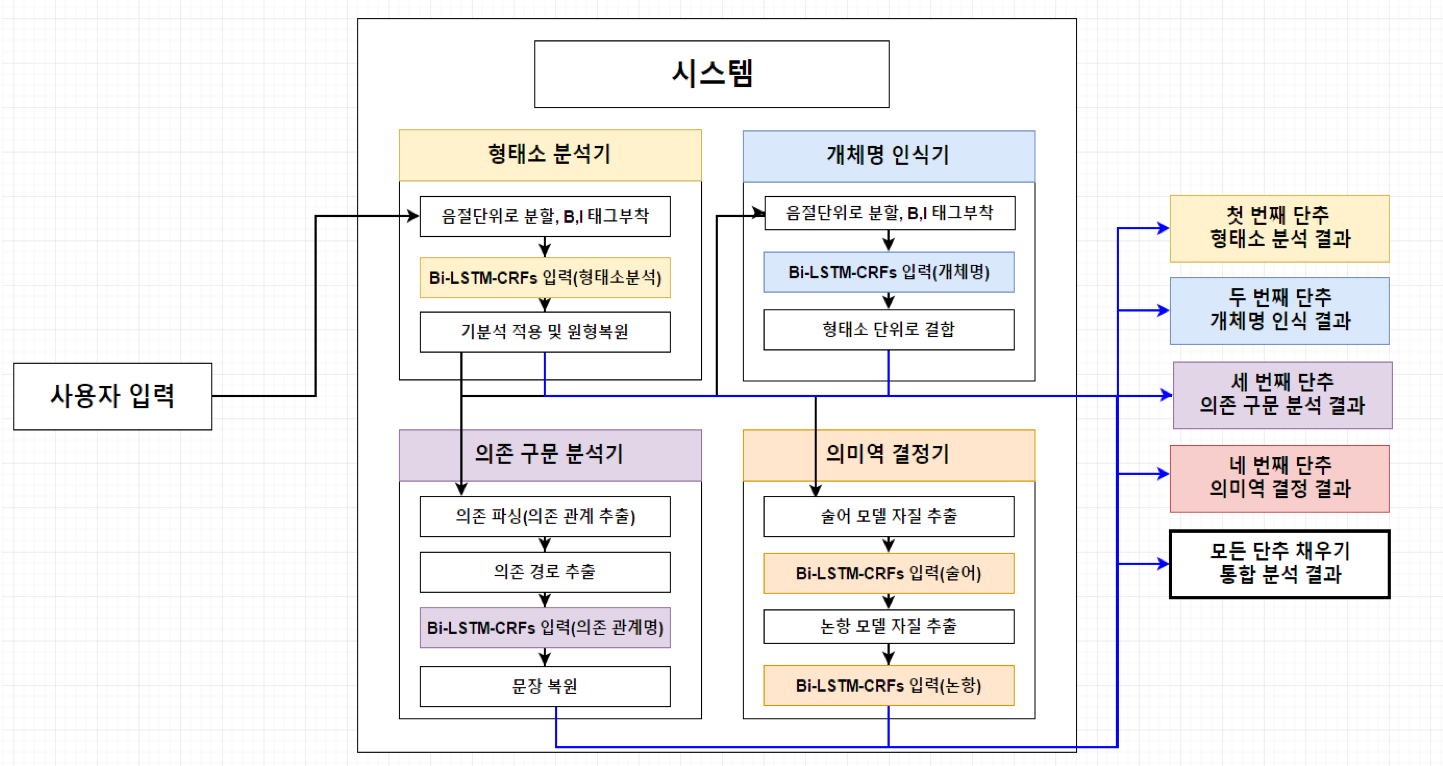
또한 이와 더불어 소형 언어모델 (sLM), RAG (Retrieval-augmented Generation) 등의 최신 자연어처리 기반 기술 역시 보유중이다.
- TBD
- TBD
7. 언어 모델 기반 딥러닝 기술
대규모 언어 모델(LLM)의 등장 이후 이를 기반으로 한 다양한 혁신적 기술들이 등장하였다. 특히 작은 언어 모델(sLM)과 검색 기반 생성(RAG, Retrieval-Augmented Generation) 기술들이 중점적으로 연구되고 있으며, 이러한 기술들은 대규모 언어 모델의 한계를 보완하면서도 높은 성능을 유지하는 것을 목표로 한다.
- sLM: LLM의 성능을 유지하면서도 더욱 경량화된 모델을 구축하는 데 초점을 맞추고 있으며, 이를 통해 자원 효율성과 실시간 처리 성능을 극대화하는 연구를 진행하고 있다.
- RAG: 대규모 데이터베이스에서 유용한 정보를 검색하고 이를 기반으로 응답을 생성하는 방식으로, 단순한 생성형 모델보다 더 신뢰성 있고 구체적인 정보를 제공하는 것을 목표로 한다.
이와 같은 기술들은 다양한 응용 분야에 적용 가능하며, 연구실은 이를 통해 자연어 처리 기술의 새로운 가능성을 탐구하고 있다.
- TBD